第06章-Search的运行机制
第06章-Search的运行机制
# 一、Search 两个阶段
Search 执行的时候实际分两个步骤运作的,即 Query-Then-Fetch
- Query 阶段:查询出文档id
- Fetch 阶段:拉取文档数据
Query 阶段过程:
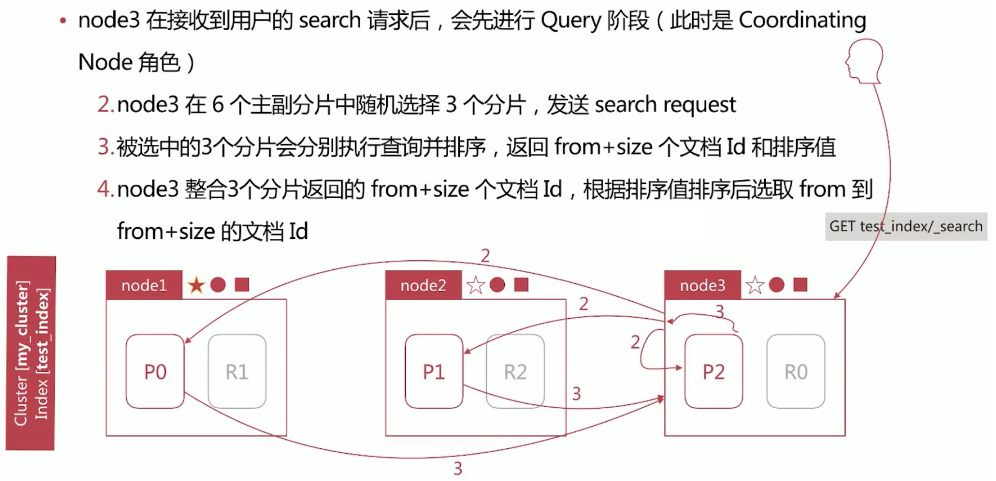
注意:上述步骤中选取的 3 个分片,必须包含索引的完整数据,即 0, 1, 2 分片必须都有,但是可以是主分片也可以是副本分片
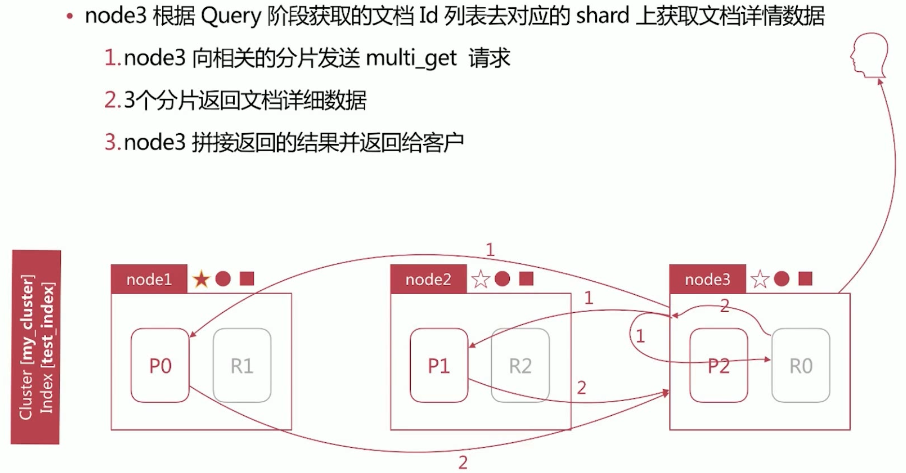
Fetch 阶段过程:
# 二、相关性算分问题
相关性算分在 shard 与 shard 间是相互独立的,也就意味着同一个 Term 的 IDF 等值在不同 shard 上是不同的。文档的相关性算分和它所处的 shard 相关。
在文档数量不多时,会导致相关性算分严重不准的情况发生。
解决思路有两个:
- 设置分片数为 1 个,从根本上排除问题,在文档数量不多的时候可以考虑该方案,比如百万到干万级别的文档数量
- 使用
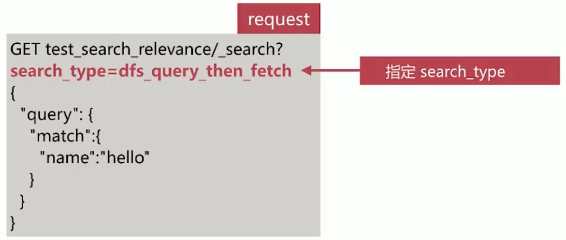
DFS Query-then-Fetch查询方式
DFS Query-then-Fetch 是在拿到所有文档后再重新完整的计算一次相关性算分,耗费更多的 cpu 和内存,执行性能也比较低下,一般不建议使用。使用方式如下:
# 三、排序
# 3.1 ES 排序操作
es 默认会采用相关性算分排序,用户可以通过设定 sorting 参数来自行设定排序规则


按照字符串排序比较特殊,因为 es 有 text 和 keyword 两种类型。如果针对 text 类型排序,如下所示:

针对 keyword 类型排序,可以返回预期结果:

# 3.2 FieldData 和 DocValues
排序的过程实质是对字段原始内容排序的过程,这个过程中 倒排索引无法发挥作用,需要用到 正排索引,也就是通过文档 id 和字段可以快速得到字段原始内容,然后按照原始内容进行排序。
es 对此提供了 2 种实现方式:
fielddata,默认禁用doc values,默认启用,除了text类型

# 3.2.1 Fielddata
Fielddata 默认是关闭的,可以通过如下 api 开启:
- 此时字符串是按照分词后的 term 排序,往往结果很难符合预期
- 一般是在对分词做聚合分析的时候开启

# 3.2.2 Doc Values
Doc Values 默认是启用的,可以在创建索引的时候关闭,如果后面要再开启 doc values,需要做 reindex 操作。如果明确知道不会按照某个字段进行排序,可以考虑关闭 doc values,最大限度的加快索引速度,减少磁盘占用。
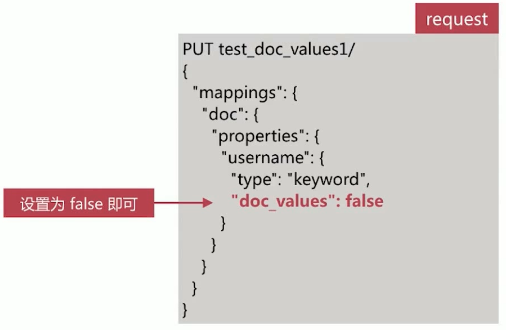
# 3.2.3 docvalue_fields 获取存储内容
可以通过该字段获取 fielddata 或者 doc values 中存储的内容

# 四、分页与遍历
es 提供了 3 种方式来解决分页与遍历的问题:
- from/size
- scroll
- search_after
| 类型 | 场景 |
|---|---|
| From/Size | 需要实时获取顶部的部分文档,且需要自由翻页 |
| Scroll | 需要全部文档,如导出所有数据的功能 |
| Search_After | 需要全部文档,不需要自由翻页 |
# 4.1 from/size
最常用的分页方案,from 指明开始位置,size 指明获取总数

深度分页问题
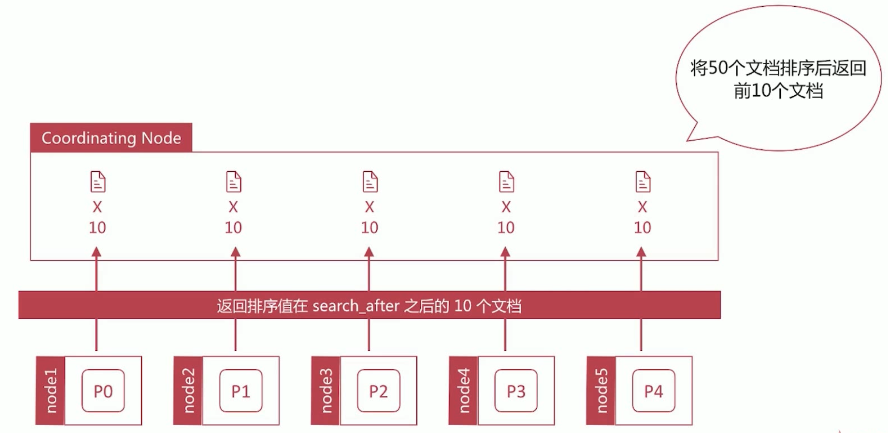
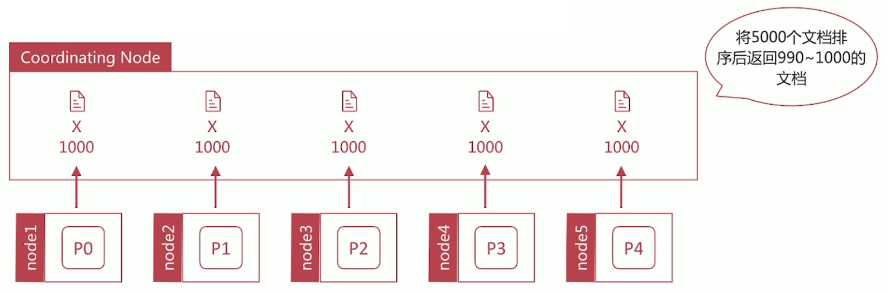
深度分页是一个经典的问题:在数据分片存储的情况下如何获取前 1000 个文档?
- 获取从 990~1000 的文档时,会在每个分片上都先获取 1000 个文档,然后再由 Coordinating Node 聚合所有分片的结果后再排序选取前 1000 个文档
- 页数越深,处理文档越多,占用内存越多,耗时越长。尽量避免深度分页,es 通过
index.max result window限定最多到 10000 条数据
# 4.2 scroll
遍历文档集的 api,以快照的方式来避免深度分页的问题。
- 不能用来做实时搜索,因为数据不是实时的
- 尽量不要使用复杂的 sort 条件,使用 _doc 最高效
- 使用稍显复杂
使用步骤:
第一步需要发起一个
scroll search,es 在收到该请求后会根据查询条件创建文档 id 合集的快照,并返回一个scroll id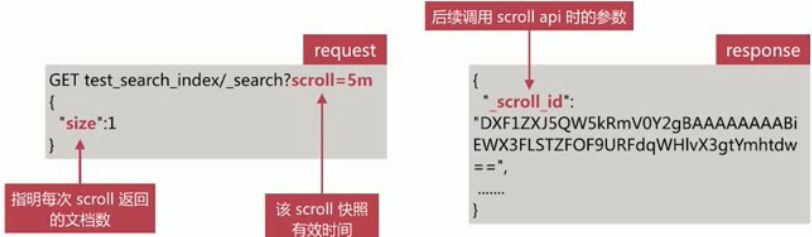
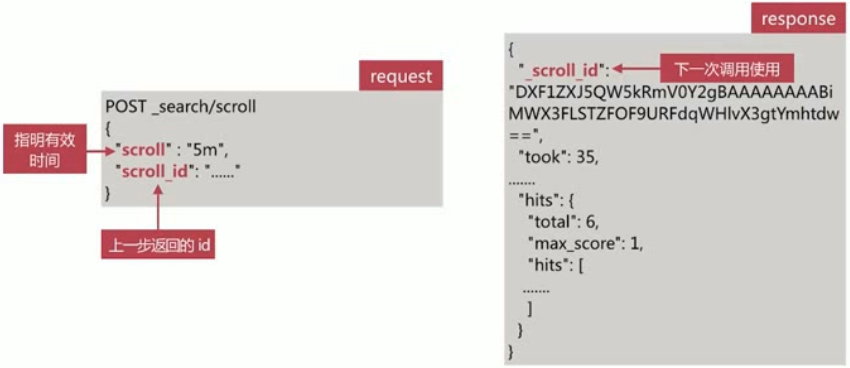
第二步使用
scroll id进行scorll操作,获取数据集合和下一批次的scroll id,不断迭代调用直到返回hits.hits数组为空时停止。这里每次调用都可以在此指定快照时间,用于刷新快照有效时间,防止失效。
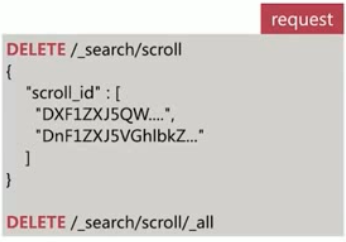
过多的 scroll 调用会占用大量内存,可以通过 clear api 删除过多的 scroll 快照:
# 4.3 search_after
search_after 也避免深度分页的性能问题,并提供实时的下一页文档获取功能。使用此功能搜索,必须指定排序值,并且排序值必须唯一。
- 缺点是不能使用from参数,即不能指定页数
- 只能下一页,不能上一页
- 使用简单
使用步骤如下:
- 为正常的搜索,但要指定 sort 值,并保证值唯一
- 为使用上一步最后一个文档的 sort 值进行查询

search_after 是如何避免深度分页问题的?
通过唯一排序值定位将每次要处理的文档数都控制在 size 内。即指定了排序值之后,每个分片只需要返回排序值之后的 size 条数据即可,不需要返回前 n 条完整数据。