第06章-Redis主从复制
第06章-Redis主从复制
# 一、 什么是主从复制
Redis单机问题
- 机器故障:单机如果机器故障,那么久无法及时提供服务
- 容量瓶颈:同时单机的内存等容量有限,无法支持耗能较大的应用
- QPS瓶颈:如果应用的访问并发过大,单机环境无法支持那么大的QPS
主从复制模式
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流向是单向的,master到slave
主从复制的作用
- 数据副本,为数据提供了多个副本,高可用分布式的基础
- 扩展读性能,可以做读写分离
# 二、主从复制配置
主从复制有两种实现方式:
slaveof命令- 配置文件
# 2.1 命令方式
在从节点上执行 slaveof 127.0.0.1 6379 命令,节点就会声明为主节点的从节点,并且异步进行数据复制。

执行 slaveof no one 生命本节点不属于任何节点的从节点,和原主节点的连接就会断开,原主节点的数据不会再复制过来。

优点:无需重启;缺点:不便于管理
# 2.2 配置方式
slaveof ip port #配置为指定节点的从节点
slave-read-only yes #配置从节点只读
2
优点:便于统一管理;缺点:需要重启
# 2.3 主从复制简单示例
配置主节点端口6379,从节点端口6380,依次启动主从节点,看到以下日志:
主节点日志:
[13964] 08 Jun 10:17:14.663 # Server started, Redis version 3.2.100
[13964] 08 Jun 10:17:14.664 * The server is now ready to accept connections on port 6379
[13964] 08 Jun 10:17:35.381 * Slave 127.0.0.1:6380 asks for synchronization //从节点请求同步
[13964] 08 Jun 10:17:35.381 * Full resync requested by slave 127.0.0.1:6380 //从节点全量复制请求
[13964] 08 Jun 10:17:35.381 * Starting BGSAVE for SYNC with target: disk //主机点执行bgsave
[13964] 08 Jun 10:17:35.411 * Background saving started by pid 29160
[13964] 08 Jun 10:17:35.493 # fork operation complete
[13964] 08 Jun 10:17:35.494 * Background saving terminated with success //bgsave成功
[13964] 08 Jun 10:17:35.496 * Synchronization with slave 127.0.0.1:6380 succeeded //同步到从节点成功
2
3
4
5
6
7
8
9
从节点日志:
[23192] 08 Jun 10:17:35.378 # Server started, Redis version 3.2.100
[23192] 08 Jun 10:17:35.379 * The server is now ready to accept connections on port 6380
[23192] 08 Jun 10:17:35.379 * Connecting to MASTER 127.0.0.1:6379 //连接主节点
[23192] 08 Jun 10:17:35.379 * MASTER <-> SLAVE sync started //主从复制已经开始
[23192] 08 Jun 10:17:35.380 * Non blocking connect for SYNC fired the event.
[23192] 08 Jun 10:17:35.380 * Master replied to PING, replication can continue...
[23192] 08 Jun 10:17:35.381 * Partial resynchronization not possible (no cached master)
[23192] 08 Jun 10:17:35.411 * Full resync from master: 7b131e9006776eeef6cd5e3860be0d4eb2059983:1 //拿到主节点的run_id
[23192] 08 Jun 10:17:35.496 * MASTER <-> SLAVE sync: receiving 75 bytes from master //从主节点接收了数据
[23192] 08 Jun 10:17:35.498 * MASTER <-> SLAVE sync: Flushing old data //清除老数据
[23192] 08 Jun 10:17:35.498 * MASTER <-> SLAVE sync: Loading DB in memory //加载到内存
[23192] 08 Jun 10:17:35.498 * MASTER <-> SLAVE sync: Finished with success //同步成功
2
3
4
5
6
7
8
9
10
11
12
从上述日志种可以看到主从同步的过程,其中有以下注意点:
- 主从辅助前主节点会做bgsave操作生成rdb文件
- 从节点需要拿到主节点的run_id,进行主从复制
启动 redis-cli 连接主节点,执行 info replicatin,可以查看节点角色
127.0.0.1:6379> info replication
# Replication
role:master # 角色,master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=1233,lag=1
master_repl_offset:1233 # 偏移量
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:1232
2
3
4
5
6
7
8
9
10
相应的查看连接从节点,查看角色是 slave。还有偏移量等数据。
# 三、全量复制和部分复制
先介绍几个概念
run_id:redis节点每次启动都会随机分配一个run_id,用来标识改redis节点。(重启之后就变了)
> redis-cli -p 6379 info server | grep run_id run_id:7b131e9006776eeef6cd5e3860be0d4eb20599831
2例如,主从关系中,如果从节点发现主节点的 run_id 发生了变化,那可能是主节点重启了或发生了什么重大变化,这时候从节点就需要将数据全量复制过来。
偏移量:主从复制过程中,标记复制进度的变量
# 3.1 全量复制
下图展示了全量复制的过程
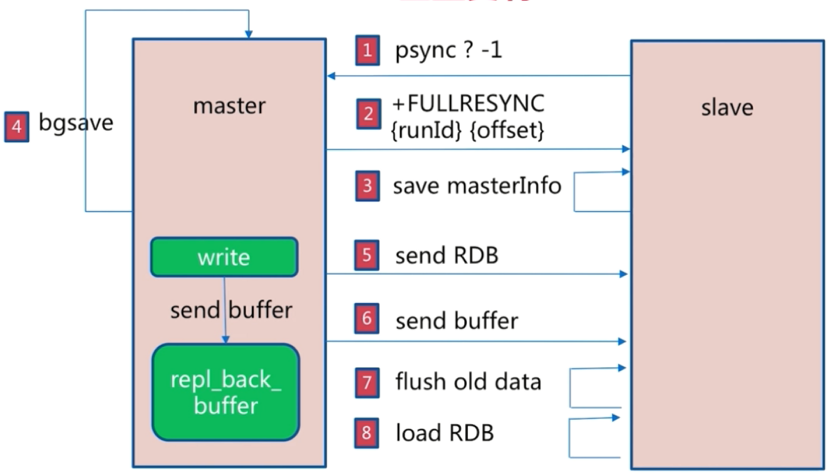
- 从节点发出
psync <master_run_id> <offset>命令,有 run_id 和偏移量两个参数,第一次不知道这两个参数值,就发出psync ? -1表示做全量复制 - 主节点收到全量复制请求,会告诉从节点自己的 run_id 和偏移量
- 从节点保存主节点回传的基本信息
- 主节点会执行bgsave操作生成快照,同时将同步过程中新的写入命令记录到复制缓冲区
repl_back_buffer中 - 主节点发送rdb快照数据到从节点
- 主节点将复制期间存在复制缓冲区
repl_back_buffer中的新写入命令发送到从节点 - 从节点清除旧数据
- 从节点加载rdb文件数据和buffer数据
明白了全量复制的过程,下面分析下全量复制的开销:
- bgsave时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载RDB的时间
- 可能的AOF重写时间:从节点最后在家rdb成功后,如果开启了AOF,可能会进行一次AOF重写
全量复制开销大,而且假如主从复制过程中主从节点间的网络发生抖动,可能会丢失部分数据。redis 2.8之前为解决部分数据丢失,会再次进行一次全量复制,但是全量复制开销大,所以2.8之后提供了部分复制功能来解决这个问题。
# 3.2 部分复制
下图展示了部分复制的过程
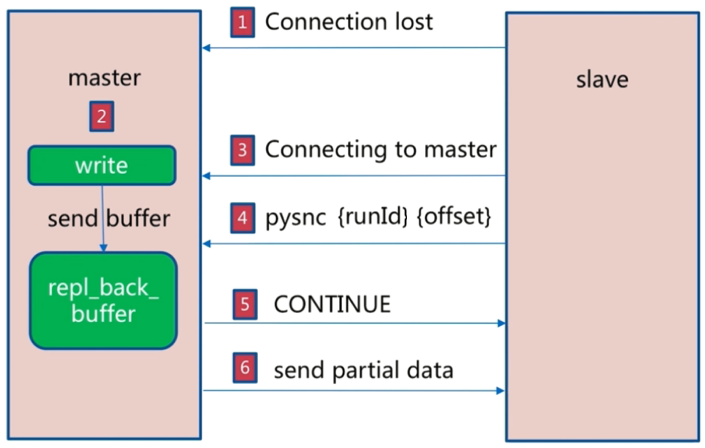
- 如果主从连接断开了
- 主节点复制缓冲区存有新的写入命令
- 从节点重新连接到主节点之后
- 从节点执行
psync <master_run_id> <offset>,告知主节点复制偏移量 - 如果主节点发现偏移量在复制缓冲区内范围内,说明还没错过很多数据,如果不在就表示已经错过了很多数据了
- 偏移量在复制缓冲区范围内的话,主节点会 CONTINUE,继续将偏移量到缓冲区结尾的数据发送到从节点(如果不在范围内则全量复制)
实际中可以将复制缓冲区的容量调大些(默认 1MB),这样如果从节点和主节点断开了,重连冲 psync 的偏移量命中复制缓冲区的可能性大些,从而避免的全量复制的开销。
参考文档:
# 四、故障处理
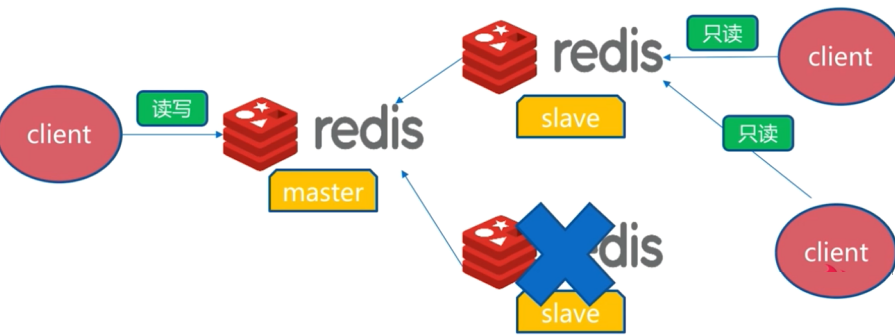
slave发生故障
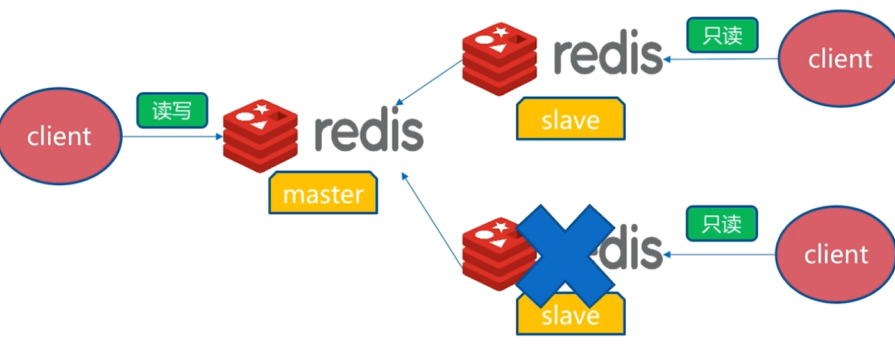
如图,如果slave发生故障,需要将读取这个slave的客户端切到正常运行的slave节点上。
master发生故障
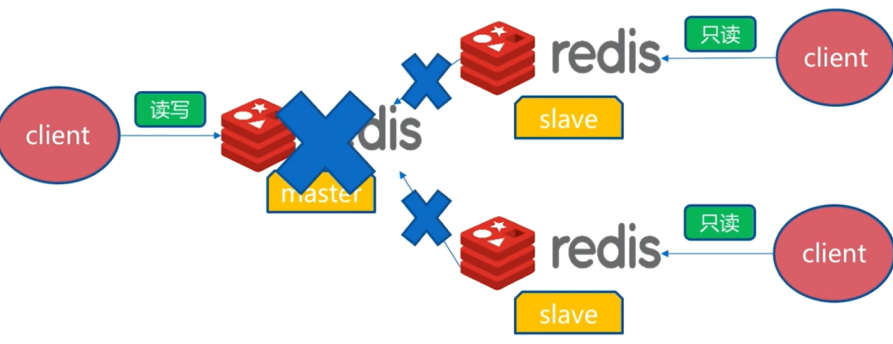
如果master故障,可以将其中一个slave设置成主节点
slaveof no one, 然后将别的从节点归属到新的主节点上,再继续对外提供服务。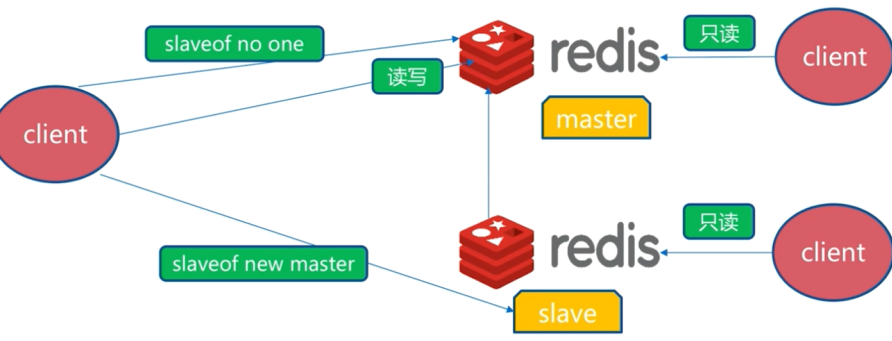
上述故障处理都需要一定时间,不能自动处理,后面介绍的 redis-sentinel 将有更优的处理方式。
# 五、开发运维中的问题
# 5.1 读写分离
读写分离:读流量分摊到从节点。
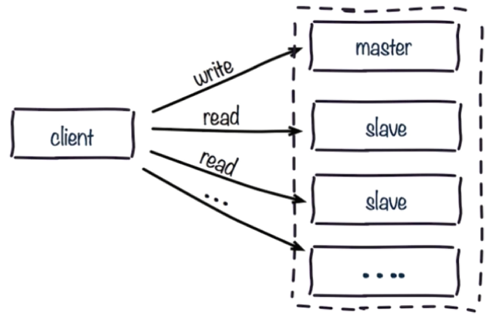
可能遇到问题:
- 复制数据延迟
- 读到过期数据:例如主节点删除了数据,主从复制不及时,客户端从从节点读到了已删除的数据
- 从节点故障
# 5.2 主从配置不一致
- 例如maxmemory不一致:丢失数据
- 例如数据结构优化参数(例如hash-max-ziplist-entries):内存不一致
# 5.3 规避全量复制
- 第一次全量复制
- 第一次不可避免
- 小主节点、低峰
- 节点运行ID不匹配
- 主节点重启(运行ID变化)
- 故障转移,例如哨兵或集群
- 复制积压缓冲区不足
- 网络中断,部分复制无法满足
- 增大复制缓冲区配置rel_backlog_size,网络“增强”。
# 5.4 规避复制风暴
复制风暴:如果主节点宕机重启后,run_id发生变化,左右的从节点都要做主从复制。这个过程对CPU、内存、网络又有很多的开销。
单主节点复制风暴:
- 问题:主节点重启,多从节点复制
- 解决:更换复制拓扑
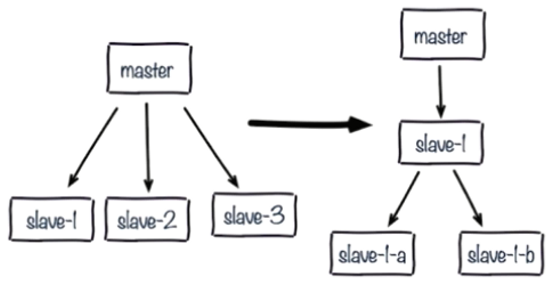
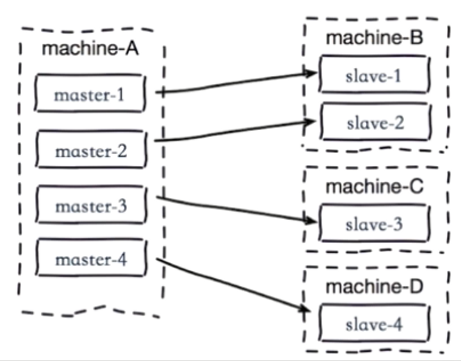
单机器复制风暴
- 如下图:机器宕机后,大量全量复制
- 主节点分散多机器