 第05章-存储引擎
第05章-存储引擎
# 一、MySQL 常见的存储引擎

# 1.1 MyISAM 引擎
MyISAM 的特点
非事务型存储引擎
其他数据库对事务的支持是通过数据库服务层实现的,MySQL 对事务的支持的在存储引擎层实现的。
以堆表方式存储
也就是说存储在 MyISAM 存储引擎中的数据是没有特定顺序的,不像存在聚簇索引中的表,可以按照聚簇索引的顺序存储。MyISAM 存储引擎中并不存在聚簇索引的概念,索引的叶子节点直接指向数据的物理地址,而不是聚簇索引的位置,因此也避免的回表二次查找操作,对于大表的查询性能有所提高。
使用表级锁
MyISAN 存储引擎中查询数据会对表加共享锁,更新操作会对表加排他锁。所以读写操作之间会相互阻塞,所以 MyISAM 不适合高并发读写的场景。
支持Btree索引,空间索引,全文索引
数据和索引是分别存储的,数据存储在 MYD 文件中,索引存在 MYI 文件中
MyISAM 存储引擎可以修复索引和压缩数据
MyISAM 使用场景
- 读操作远远大于写操作的场景
- 不需要使用事务的场景
# 1.2 CSV 引擎交换数据
CSV 的特点
非特务型存储引擎
数据以 CSV 格式存储
以逗号分隔字段,以换行分割记录行,以双引号包裹字符串。可以直接查看和编辑 CSV 引擎的数据文件。
所有列都不能为 NULL
不支持索引
CSV 的使用场景
- 做为数据交换的中间表使用,如将 CSV 文件直接导入数据库,或直接导出。
# 1.3 Archive 引擎存储归档数据
Archive 的特点
- 只支持 insert 和 select 操作,不支持 update 和 delete
- 可以实现高并发的插入
- 只支持在自增 id 上建立索引
Archive 的使用场景
- 日志和数据采集类应用
- 数据归档存储
# 1.4 Memory 引擎
Memory 的特点
- 非事务型存储引擎
- 数据保存在内存中,Memory 表的结构在重启以后还会保留,但数据会丢失
- 所有字段长度固定
- 支持 Btree 和 Hash 素引
Memory 的使用场景
- 用于缓存字典映射表
- 缓存周期性分析数据
# 1.5 InnoDB 引擎
InnoDB 的特点
- 事务型存储引擎支持 ACID
- 数据按主键聚集存储
- 支持行级锁及 MVCC
- 支持 Btree 和自适应 Hash 索引
- 支持全文和空间索引
InnoDB 的使用场景
- 大多数 OLTP 场景
# 1.6 NDB 引擎
NDB 引擎的特点
- 事务型存储引擎
- 数据存储在内存中
- 支持行级锁
- 唯一支持高可用集群的存储引擎
- 支持 Ttree 索引
NDB 的使用场景
- 需要数据完全同步的高可用场景
# 二、详解 InnoDB
# 2.1 Online DDL
Online DDL:在线修改表结构,MySQL 5.6 以上支持,相较于一般 DDL,它在实现修改表结构的同时,依然允许 DML 操作。
参考:
# 2.1.1 不支持在线修改表结构的情况:

- 在给 InnoDB 表建立全文索引或空间索引时,由于需要增加隐藏列记录索引信息,所以就需要重新建表,无法进行在线操作。当再次在同一表上建立全文索引或空间索引时就可以在线修改表结构。也就是对一个表第一次建立全文索引或空间索引时,不能在线修改。
- InnoDB 表是按照主键逻辑来进行顺序存储的,当删除主键的时候必定会对表中的数据重新排列,所以无法在线删除主键。
- InnoDB 要求所有自增的列必须是主键的一部分,所以当给一个表增加自增列时,必定会改变主键,所以也会改变表中数据的逻辑顺序,所以此操作无法在线完成。
- 对任何表的修改都要先获得这个表的元数据锁,也即是说同一个表 DDL 操作是不能够并发执行的。另外对一个长时间运行的事务已经获取了表的元数据锁,也会阻塞 DDL 的执行。
# 2.1.2 在线 DDL 存在的问题
有部分语句不支持在线 DDL
长时间的 DDL 操作会引起严重的主从延迟
无法对 DDL 操作进行资源限制
DDL 操作还需要磁盘的临时空间,当对一个大表进行 DDL 操作时,很容易出现磁盘的临时目录空间不足的情况,造成 DDL 操作的失败。
# 2.1.3 如何更安全的执行 DDL
使用第三方工具:pt-online-schema-change [OPTIONS] DSN,工具会根据建立一个在原表基础上经过修改的一个新表,再分批次将数据导入,最后重命名两张表,就完成了表的修改。修改过程中只有在最后修改表名的时候会短暂锁表,并且是分批操作也不会有很大的主从延迟。
# 2.2 事务
# 2.2.1 事务特点

# 2.2.2 InnoDB 如何实现事务
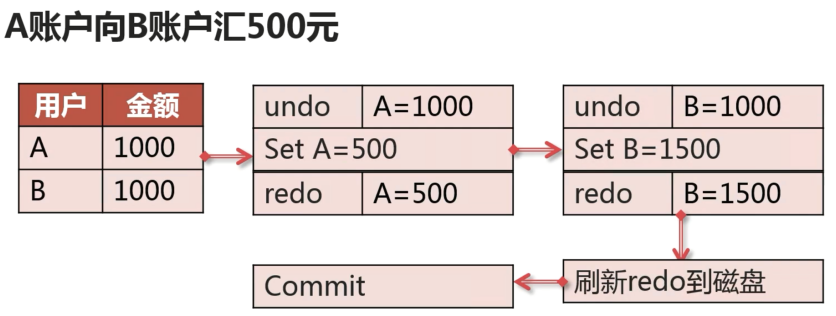
InnoDB 为实现事务,引入了回滚日志(Undo Log)和重做日志(Redo Log),这两种日志在任何支持事务的存储引擎中都是存在的。

- Undo Log 记录数据修改前的状态,如果事务执行过程中失败,就要使用 Undo Log 回滚数据。主要实现事务的原子性。
- Redo Log 记录数据修改后的状态,用于实现事务的一致性。
- 事务的隔离性是通过加锁实现的,分为共享锁和排他锁,共享锁和排他锁之间是互斥的。
- 事务的持久性由回滚日志和重做日志共同实现,在事务提交过程总如果出现了数据库的崩溃,恢复之后就要配置 Redo Log 和 Undo Log 对数据进行恢复,以保证事务的持久性。
示例:
# 2.2.3 多版本并发控制 MVCC
InnoDB 读是否会阻塞写?读写应该相互阻塞吗?
- 查询需要对资源加共享锁(S)
- 数据修改需要对资源加排它锁(x)

通过实现会发现:
客户端 A 对表中 id = 1 的记录进行修改,不提交事务,客户端 B 可以查询到 id = 1 的老数据。客户端 B 没有读到客户端 A 未提交的数据,同时客户端 A 未提交的事务也没有阻塞客户端 B 的读操作。这似乎和上面的排他锁和共享锁不兼容矛盾,InnoDB 能做到这一点是因为其利用到了 Undo Log 的多版本控制,即 MVCC。
MVCC(多版本并发控制),结合下图介绍 MVCC:
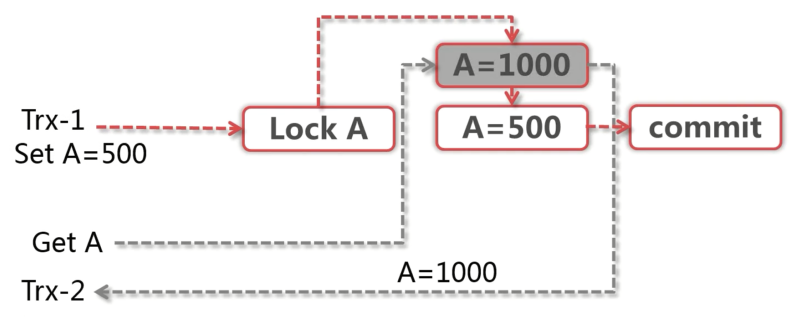
如图:
- 事务 1(Trx-1)对数据 A 进行写操作,获取到了 A 的排他锁,开始执行操作
- 事务 1 先将 A 原数据存入 Undo Log,再进行修改操作
- 事务 2(Trx-2)再事务 1 执行过程中读取数据 A,由于事务 1 对 A 加了排他锁,所以事务 2 读不到数据 A
- 此时 InnoDB 会去 Undo Log 中获取的数据 A 原先值,返回给事务 2