 第07章-索引优化
第07章-索引优化
# 一、SQL 优化的手段
- 优化 SQL 查询所涉及到的表中的索引
- 改写 SQL 以达到更好的利用索引的目的
# 二、索引
# 2.1 索引的作用
告诉存储引擎如何快速的查找到所需要的数据。
举个例子,在下图课程表的技术方向字段上创建了索引,这些值就是一个个索引节点,指向实际存储数据的物理地址,通过 mysql 索引节点就可以找到物理地址 0001 和 0003 处存着 mysql 技术方向的课程记录。如果没有索引就需要逐一扫描物理块。
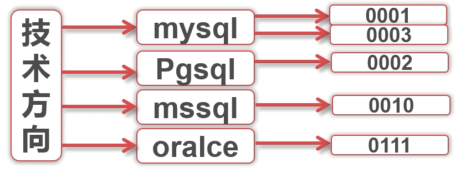
正如上面所说,索引的作用是 告诉存储引擎如何快速的查找到所需要的数据。所以 MySQL 的索引是在存储引擎层实现的,而不是服务层实现的。这就决定了不同的存储引擎在索引的工作方式上是不同的,不同的存储引擎所支持的索引类型也不同,即使同一种索引,在不同存储引擎的底层实现上也是不同的。
# 2.2 InnoDB 支持的索引类型
- Btree索引:最常用的索引类型
- 自适应的 HASH 索引:这种索引的 InnoDB 存储引擎为了优化查询而自动建立的,不需要手动管理,所以不用太关注这类索引
- 全文索引:用在字符串类型上,对中文支持不好,不建议使用(5.7 之后)
- 空间索引:建立在点线面空间数据类型之上(5.7 之后)
# 2.3 Btree 索引的特点
以 B+ 树的结构存储索引数据
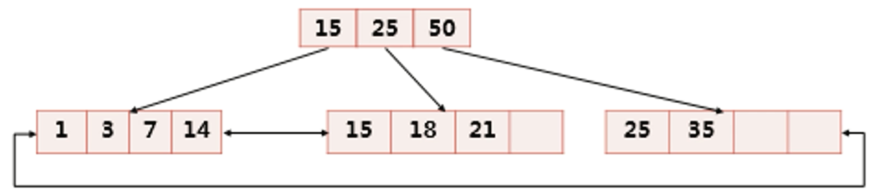
B+ 树本身是一种平衡的二叉树,每个叶子节点到根的距离都是相同的,所有索引节点都是按键值大小顺序放在同一层的叶子节点上的,并且每个叶子节点是通过指针连接的。
这种结构是为了方便查找,但是不同的存储引擎实现有所不同,MyISAM 的 Btree 索引在叶子节点上存的是记录行的物理地址,而 InnoDB 的 Btree 索引在叶子节点上存的是数据行的主键的位置。
Btree 索引适用于全值匹配的查询,如
class_name = 'MySQL',class_name in ( 'MySQL', 'Oracle' )in条件是可以使用索引的,只有当 in 里的数据量过多时,MySQL 优化器可能认为还不如使用全表扫面方式性能好,才不会走索引。Btree 索引适合处理范围查找,如
between...and、>、<等Btree 索引存在最左匹配原则
# 2.4 应该在哪些字段上建立索引
通常是需要结合需要使用的查询语句结合表中的列来建立索引的。通常在以下情况下的列建立索引:
WHERE 子句中的列
并不是 WHERE 中的所有字段都需要建立索引,通常在筛选性好的字段上建立索引,即区分度高的字段。在联合索引中,也尽量将区分度高的字段放在前面。如下例子中,可以使用 count 方法评估字段的区分度。
-- 查询性别为男,注册时间大于 2019-01-01 的用户 SELECT user_nick FROM imc_user WHERE sex = 1 AND reg_time > '2019-01-01'; -- 分析 sex 和 reg_time 字段的区分度 SELECT COUNT(DISTINCT sex) 性别数, COUNT(DISTINCT DATE_FORMAT(reg_time, '%Y-%m-%d')) 注册时间数, COUNT(*) 总记录数, COUNT(DISTINCT sex) / COUNT(*) 性别占记录数比例, COUNT(DISTINCT DATE_FORMAT(reg_time, '%Y-%m-%d')) / COUNT(*) 注册时间占记录数比例 FROM imc_user;1
2
3
4
5
6
7
8
9
10
11
12
包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
在 ORDER BY、GROUP BY 字段上建立索引可以提高排序性能,避免使用临时表。但并不是所有的情况 ORDER BY 都能使用索引,只有满足以下条件才能走索引:
- 索引列的顺序和 ORDER BY 中字段顺序相同
- 索引列中的方向和 ORDER BY 中字段指定的顺序相同
- 在多个表的关联字段中,ORDER BY 中的字段要全部在关联表的第一张表中
多表 JOIN 的关联列
# 2.5 如何选择复合索引键的顺序
区分度最高的列放在联合索引的最左侧
使用最频繁的列放到联合索引的最左侧
尽量把字段长度小的列放在联合索引列的最左侧
注:对于 innoDB 的数据页默认大小是 16K,键值的长度大小越小,一页所能承载的记录就越多,相应查询的 IO 性能就越好。详细可参考 InnoDB 数据页 (opens new window)
# 2.6 Btree 索引的限制
- 必须符合最左匹配原则
NOT IN和<>条件,无法使用索引- 索引列上使用表达式或函数,无法使用索引
# 2.7 索引使用的误区
索引越多越好(x)
索引不是越多越好,索引可以增加查询效率,但是会降低插入和更新的效率。甚至另一些情况会降低查询效率,这是因为 MySQL 优化器在优化查询的时候,会根据统计信息,对每一个可以用到的索引进行评估,以生成一个最优的执行计划,而如果我们同时拥有很多索引可以用于查询的话,这就增加了 MySQL 生成查询计划的时间,这样也就降低了 SQL 的查询性能。
使用 in 列表查询不能使用索引
如果使用 or 运算符关联多个条件的话,可能是无法用到索引的,但是 in 列表不同于 or,是可以用到索引的。但是如果满足 in 列表条件的数据过多,还不如全表扫面的时候,MySQL 优化器就会选择不走索引。
查询过滤顺序必需同索引键顺序相同才可以使用到索引
WHERE 条件字段只要能满足复合索引最左匹配原则,不需要按从左到右顺序编写 WHERR 子句,MySQL 优化器会会自动调整顺序以适应索引键值顺序,从而正确使用索引。
# 三、SQL 改写
使用 outer join 代替 not in
-- 查询出不存在课程的分类名称 SELECT class_name FROM imc_class WHERE class_id NOT IN ( SELECT class_id FROM imc_course ) -- 使用左外连接,筛选右表为 null 的数据行 SELECT class_name FROM imc_class a LEFT JOIN imc_course b ON a.class_id = b.class_id WHERE b.class_id IS NULL1
2
3
4
5
6
7
8
9
10
11
12上述优化手段在 MySQL 8.0 的版本中可以由 MySQL 优化器自行完成。
使用 CTE 代替子查询(8.0 新功能)
使用子查询和 CTE 都会生成临时表,只不过 CTE 生成的临时表是一个匿名临时表,并且可以多次引用。
拆分复杂大 SQL 为多个简单小 SQL
巧用计算列优化查询(5.7+)
-- 需求:查询对于内容,逻辑和难度三项评分之后大于28分的用户评分。 EXPLAIN SELECT * FROM imc_classvalue WHERE (content_score + level_score + logic_score) > 28 -- 添加计算列字段 ALTER TABLE imc_classvalue ADD COLUMN total_score DECIMAL(3,1) AS (content_score + level_score + logic_score); -- 在计算列上添加索引 CREATE INDEX idx_totalScore ON imc_classvalue(total_score);1
2
3
4
5
6
7
8
9