 第04章-Search API
第04章-Search API
# 一、Search API 概览
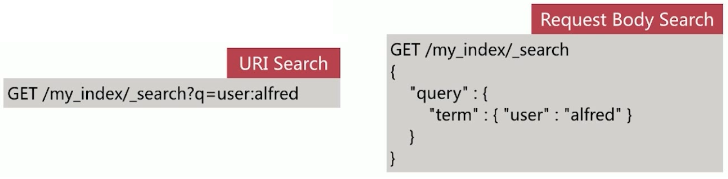
实现对 es 中存储的数据进行查询分析,endpoint 为 _search,如下所示:

查询主要有两种形式
- URI Search:操作简便,方便通过命令行测试,仅包含部分查询语法
- Request Body Search:es 提供的完备查询语法 Query DSL (Domain Specific Language)
# 二、URI Search
# 2.1 搜索方式介绍
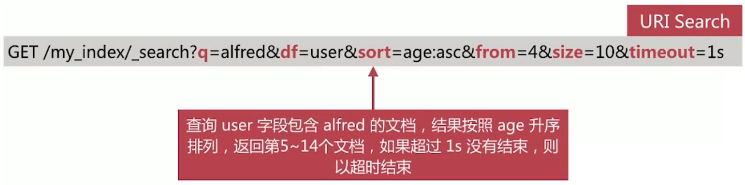
通过 url query 参数来实现搜索,常用参数如下:
q:指定查询的语句,语法为 Query String Syntaxdf:q 中不指定字段时默认查询的字段,如果不指定,es 会查询所有字段sort:排序from,size:用于分页timeout:指定超时时间,默认不超时
# 2.2 搜索语法
# 匹配规则
term 与 phrase:
q=alfred way 等效于 alfred OR way q="alfred way" 词语查询,要求先后顺序1
2泛查询:
q=alfred等效于在所有字段去匹配该 term指定字段:
q=name:alfredGroup 分组设定:使用括号指定匹配的规则
q=(quick OR brown) AND fox q=status:(active OR pending) title:(full text search)1
2
可以通过加 profile 请求体,查看实际查询条件


# 布尔操作符
AND(&&), OR(|), NOT(!)
q=name:(tom NOT lee) 注意大写,不能小写1+-分别对应 must 和 must_notq=name:(tom+lee-alfred)`,`q=name:(lee&&lalfred)|(tom&&lee&&lalfred))`1+在 url 中会被解析为空格,要使用 encode 后的结果才可以,为%2B
# 范围查询,支持数值和日期
区间写法,闭区间用
[],开区间用{}age:[1 TO 10] 意为 1<=age<=10 age:[1 TO 10} 意为 1<=age<10 age:[1 TO] 意为 age>=1 age:[* TO 10] 意为 age<=101
2
3
4算数符号写法
age:>=1 age:(>=1&&<=10) 或者 age:(+>=1+<=10)1
2
# 通配符查询
?代表1个字符,*代表0或多个字符name:t?m name:tom* name:t*m*1
2
3通配符匹配执行效率低,且占用较多内存,不建议使用
如无特殊需求,不要将
?或*放在最前面
# 正则表达式匹配
name:/[mb]oat/
# 模糊匹配 fuzzy query
name:roam~1:匹配与 roam 差 1 个 character 的词,比如 foam、roams 等
# 近似度查询 proximity search
"fox quick"~5:以 term 为单位进行差异比较,比如 "quick fox","quick brown fox" 都会被匹配
# 三、Request Body Search
# 3.1 搜索方式介绍
将查询语句通过 http request body 发送到 es,主要包含如下参数
- query:符合 Query DSL 语法的查询语句
- from、size、timeout、sort 等等
# 3.2 Query DSL
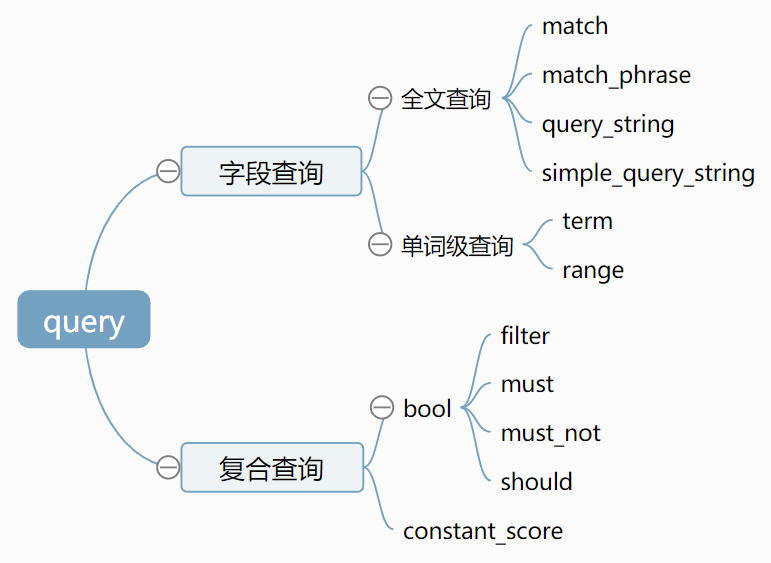
基于JSON定义的查询语言,主要包含如下两种类型:
- 字段类查询:如 term, match, range 等,只针对某一个字段进行查询
- 复合查询:如 bool 查询等,包含一个或多个字段类查询或者复合查询语句
具体参考官方文档:Query DSL (opens new window)
Query DSL 结构包含主要包含下图部分,后面会详细介绍相关查询的含义和语法。
# 3.3 相关性算分
在介绍详细介绍查询方式之前,先学习下 es 的相关性算分。
相关性算分是指文档与查询语句间的相关度,英文为 relevance,通过倒排索引可以获取与查询语句相匹配的文档列表,那么如何 将最符合用户查询需求的文档放到前列 呢?本质是一个排序问题,排序的依据是相关性算分。
# 3.3.1 相关性算分因素
相关性算分的几个重要概念如下:
- Term Frequency(TF) 词频,即单词在该文档中出现的次数。词频越高,相关度越高
- Document Frequency(DF) 文档频率,即单词出现的文档数
- Inverse Document Frequency(IDF) 逆向文档频率,与文档频率相反,简单理解为1/DF。即单词出现的文档数越少,相关度越高
- Field-length Norm 文档越短,相关性越高
# 3.3.2 相关性算分模型
ES目前主要有两个相关性算分模型,如下:
- TF/IDF 模型
- BM25 模型,5.x 之后的默认模型
TF/IDF 模型 是 Lucene 的经典模型,其计算公式如下
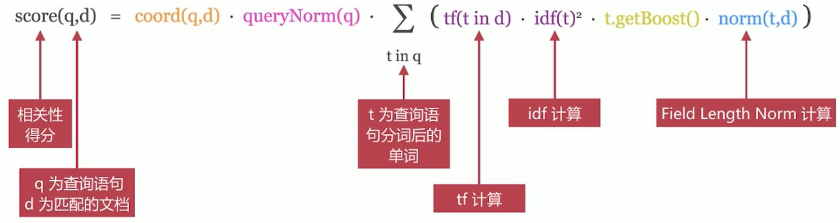
可以通过 explain 参数来查看具体的计算方法,但要注意:
- es 的算分是按照 shard 进行的,即 shard 的分数计算是相互独立的,所以在使用 explain 的时候注意分片数。
- 可以通过设置索引的分片数为 1 来避免这个问题
BM25 模型 中 BM 指 Best Match,25 指迭代了 25 次才计算方法,是针对 TF/IDF 的一个优化,其计算公式如下:
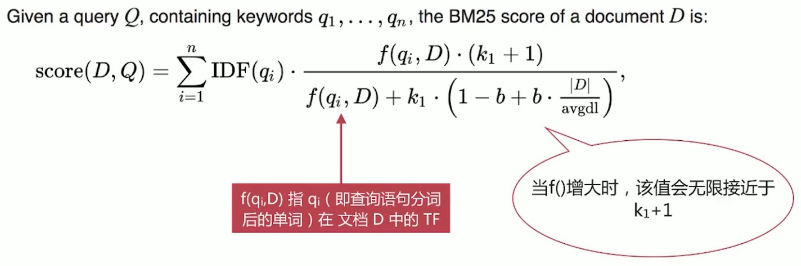
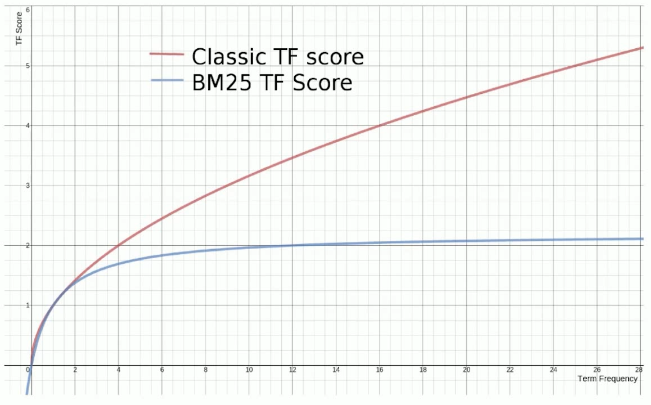
BM25 相比 TF/IDF 的一大优化是降低了 TF(词频)在过大时的权重
至此,了解了相关性算分之后,开始详细介绍查询方式和语法。
# 四、字段查询和复合查询
前面介绍 Query DSL 时,提到 Query DSL 主要包含包含字段类型查询和符合查询。
# 4.1 字段查询
字段类查询主要包括以下两类:
- 全文查询:针对 text 类型的字段进行全文检索,会对查询语句先进行分词处理,如 match,match_phrase 等 query 类型。
- 单词级查询:不会对查询语句做分词处理,直接去匹配字段的倒排索引,如 term,terms,range 等。
# 4.1.1 全文查询
全文查询使你能够搜索分析过的文本字段,例如电子邮件正文。查询时使用的分词器和索引时分词器相同。
具体可参考官方文档:Full text queries (opens new window)
全文查询包含以下具体方式:
# Match Query
- 对字段作全文检索,最基本和常用的查询类型,API示例如下

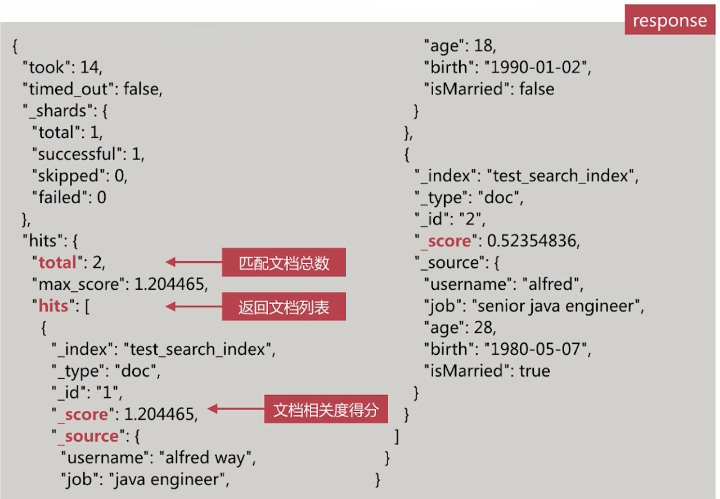
- Match Query具体流程如下
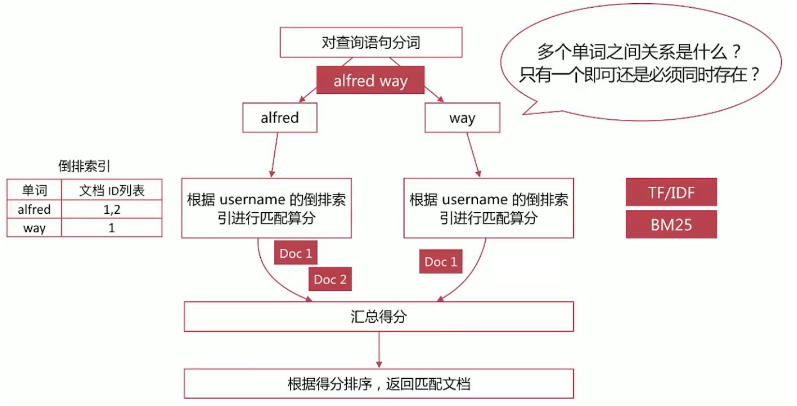
通过 operator 参数可以控制单词间的匹配关系,可选项为
or和and以下示例表示 文档中 alfred 和 way 必须同时存在

通过 minimum_should_match 参数可以控制需要匹配的单词数
以下示例表示 文档最少含有条件中的两个单词

# Match Phrase Query
对字段作检索,有顺序要求,API 示例如下:

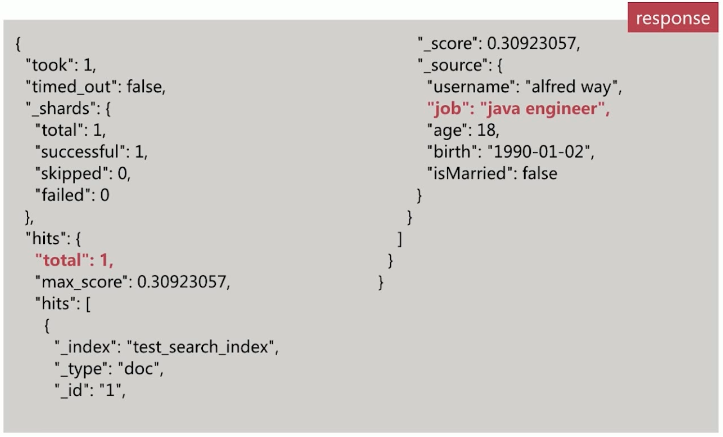
通过 slop 参数可以控制单词间的间隔
以下示例表示 关键词之间允许存在一个词的间隔距离


# Query String Query
类似于 URI Search 中的 q 参数查询


# Simple Query String Query
类似 Query String,但是会忽略错误的查询语法,并且仅支持部分查询语法
其常用的逻辑符号如下,不能使用 AND、OR、NOT 等关键词:
+代指 AND|代指 OR-代指 NOT

# 4.1.2 单词级查询
使用单词级别的查询,根据结构化数据中的精确值查找文档。与全文查询不同,词级查询不进行分词。相反,单词级查询与文档中的字段进行精确匹配。
具体可参考官方文档:Term level queries (opens new window)
单词级查询包含以下具体方式:
# Term Query
将查询语句作为整个单词进行查询,即不对查询语句做分词处理,如下所示:

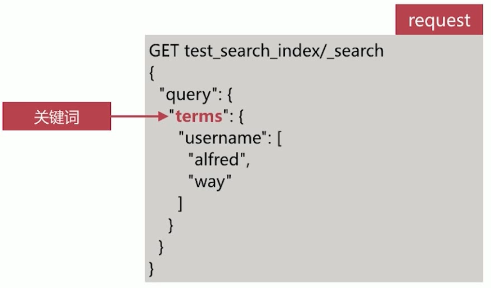
使用 terms 一次传入多个单词进行查询,如下所示:
# Range Query
范围查询主要针对数值和日期类型,如下所示:
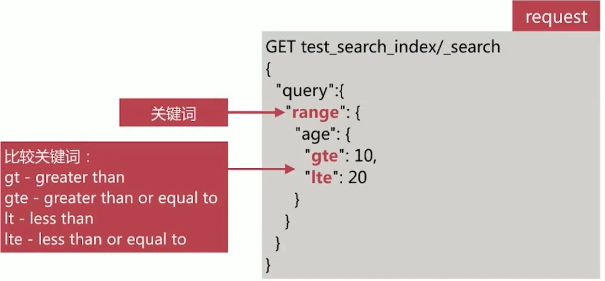
针对日期做查询,如下所示
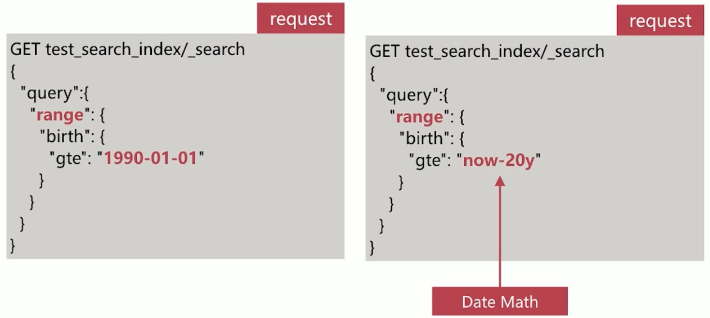
针对日期提供的一种更友好地计算方式,格式如下:
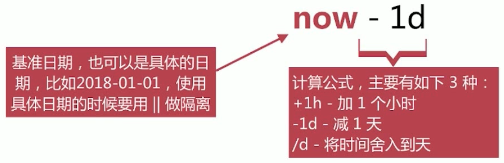
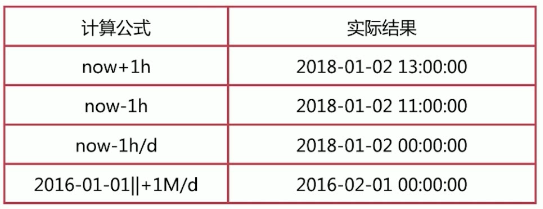
主要时间单位:y-years,M-months,w-weeks,d-days,h-hours,m-minutes,s-seconds
假设 now 为 2018-01-02 12:00:00,那么如下的计算结果实际为:
# 4.2 复合查询
复合查询是指包含字段类查询或复合查询的类型,主要包括以下几类:
- constant_score query:包装另一个查询的查询,但在过滤器上下文中执行它。
- bool query:组合一个或多个布尔查询子句。
- dis_max query:接受多个查询并返回与任何查询子句匹配的文档。
- function_score query:允许修改查询结果文档的相关性得分。
- boosting query:返回匹配 positive 子句的文档,同时减少也匹配 negative 子句文档的分数。
具体参考官方文档:Compound Queries (opens new window)
下面重点介绍 constant_score query 和 bool query
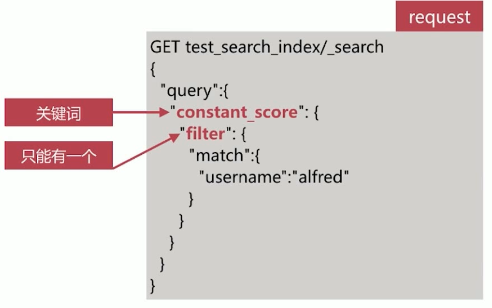
# 4.2.1 constant_score query
包装过滤器查询,并将所有结果的相关性得分都设置成 boost 参数设置的值,默认为 1.0,然后将过滤后的文档放回。
# 4.2.2 bool query
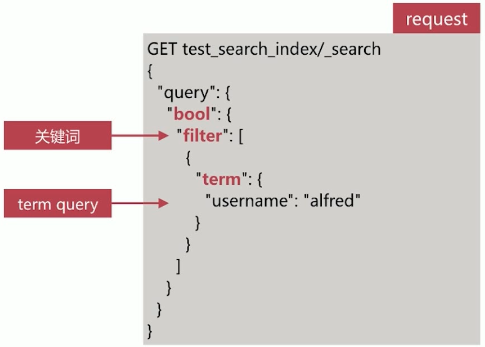
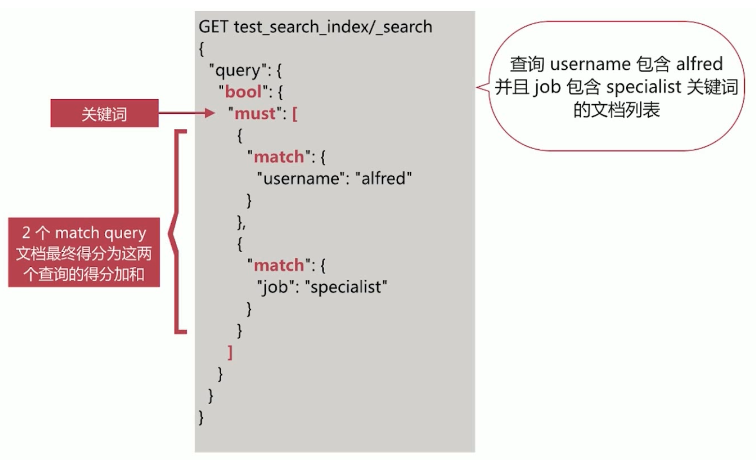
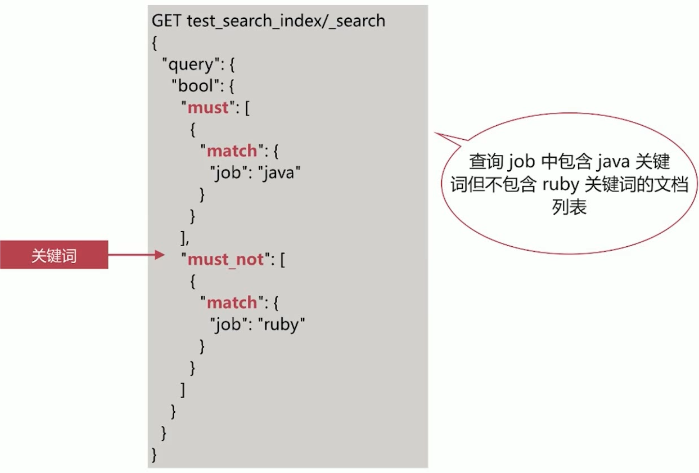
布尔查询,由一个或多个布尔子句组成,主要包含如下4个:
| 子句 | 含义 |
|---|---|
| filter | 只过滤符合条件的文档,不计算相关性得分 |
| must | 文档必须符合 must 中的所有条件,会影响相关性得分 |
| must_not | 文档必须不符合 must_not 中的所有条件,不会影响相关性得分 |
| should | 文档可以符合 should 中的条件,会影响相关性得分 |
Bool 查询的 API 如下所示

Filter 查询只过滤符合条件的文档,不会进行相关性算分
- es 针对 filter 会有智能缓存,因此其执行效率很高
- 做简单匹配查询且不考虑算分时,推荐使用 filter 替代 query 等
must
must_not
should
should 使用分两种情况:
- bool 查询中只包含 should,不包含 must 查询
- bool 查询中同时包含 should 和 must 查询
只包含 should 时,文档必须满足至少一个条件
minimum should_match 可以控制满足条件的个数或者百分比
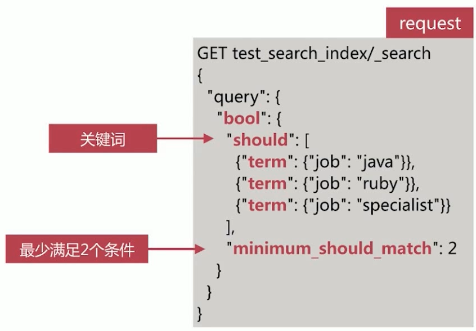
同时包含 should 和 must 时,文档不必满足 should 中的条件,但是如果满足条件,会增加相关性得分

# 五、Query 和 Filter 上下文
默认情况下,Elasticsearch 按相关性分数对匹配的搜索结果进行排序,相关性分数衡量每个文档与查询的匹配程度。虽然每种查询类型可以不同地计算相关性分数,但分数计算还取决于查询子句是在查询还是过滤器上下文中运行。
在 Query 上下文中,查询子句回答了 “此文档与此查询子句匹配程度如何?” 除了判断文档是否匹配外,查询子句还会计算 _score 元数据字段中的相关性分数 。
在 Filter 上下文中,查询子句回答问题 “此文档是否与此查询子句匹配?”,答案是简单的“是”或“否”——不计算分数。过滤上下文主要用于过滤查询结果文档。
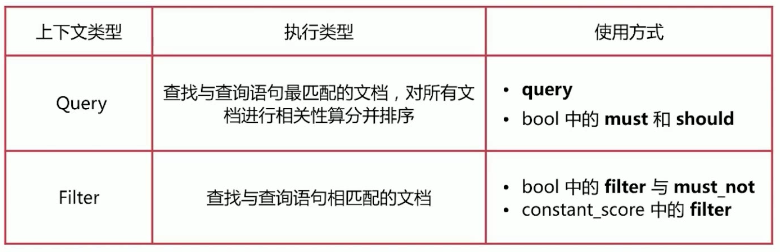
Query 和 Filter 上下文使用示例:

具体参考官方文档:Query and filter context (opens new window)
# 六、文档计数和字段过滤
# 6.1 文档计数
获取符合条件的文档数,endpoint 为 _count

# 6.2 文档字段过滤
过滤返回结果中 _source 中的字段,主要有如下几种方式:
