 第09章-缓存设计与优化
第09章-缓存设计与优化
# 一、缓存的收益与成本
# 1.1 收益
加速读写
通过缓存加速读写速度:CPUL1/L2/L3 Cache、Linux page Cache加速硬盘读写、浏览器缓存、Ehcache缓存数据库结果。
降低后端负载
后端服务器通过前端缓存降低负载:业务端使用Redis降低后端MySQL负载等
# 1.2 成本
- 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关。
- 代码维护成本:多了一层缓存逻辑。
- 运维成本:例如Redis Cluster
# 1.3 使用场景
- 降低后端负载: 对高消耗的SQL:join结果集/分组统计结果缓存。
- 加速请求响应: 利用Redis/Memcache优化IO响应时间
- 大量写合并为批量写: 如计数器先Redis累加再批量写DB
# 二、缓存更新策略
# 2.1 缓存更新方式
- LRU/LFU/FIFO 算法剔除:例如 maxmemory-policy。
- 超时剔除:例如 expire。
- 主动更新:开发控制生命周期
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LIRS 算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 低 |
| 主动更新 | 强 | 高 |
两条建议:
- 低一致性:最大内存和淘汰策略
- 高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底。
# 2.2 Redis 淘汰策略
Redis 通过 maxmemory-policy 配置数据的淘汰策略,一共六种淘汰策略,分成四大类
- lru:最近最少使用的淘汰
- allkeys:所有
- volatile:设置过期时间的
- ttl:从已设置过期时间中挑选将要过期的淘汰
- random:数据中随机淘汰
- allkeys:所有
- volatile:设置过期时间的
- no-enviction:禁止驱逐,直接报错
# 三、缓存粒度控制
缓存数据时,是否需要缓存全量信息。

- 通用性:全量属性更好
- 占用空间:部分属性更好
- 代码维护:表面上全量属性更好
# 四、缓存穿透
问题描述:缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
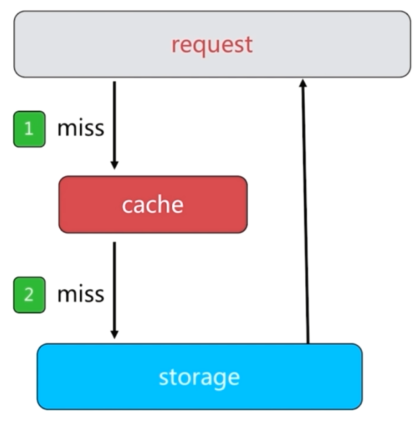
原因:
- 业务代码自身问题
- 恶意攻击、爬虫等等
如何发现:
- 业务的相应时间
- 业务本身问题
- 相关指标:总调用数、缓存层命中数、存储层命中数
解决方案:
接口参数校验,不合法参数直接返回(如 id<0)
缓存空对象
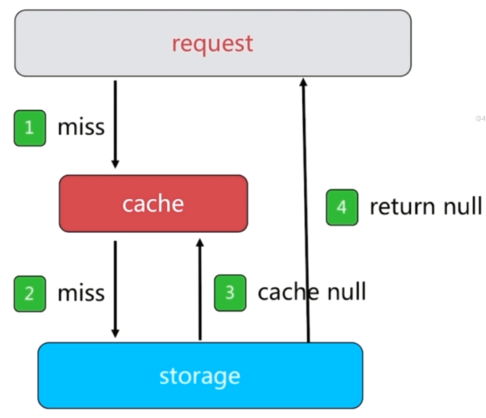
本方案有两个问题:
- 需要更多的键。
- 缓存层和存储层数据“短期”不一致。
布隆过滤器拦截
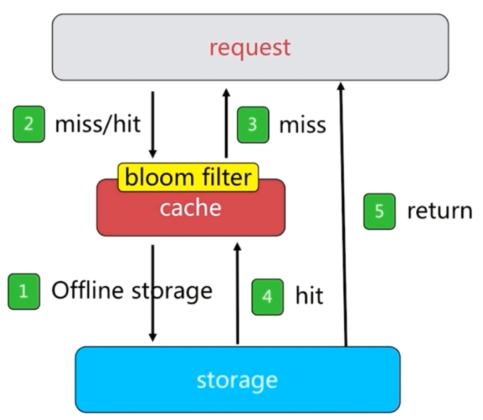
# 五、缓存击穿
问题描述:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
解决方案:
- 加互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
- 热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。
# 六、缓存雪崩
问题描述:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 过期时间打散。既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
- 热点数据不过期。该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
- 加互斥锁。该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
# 七、无底洞问题优化
问题描述:
- 2010年,Facebook有了3000个Memcache节点。
- 发现问题:“加”机器性能没能提升,反而下降。
以mget为例,mget需要客户端根据节点不同数据分批查询。一次mget操作随着节点的个数越来越多,网络次数也会越来越多,对客户端一次命令的执行效率会有很大的影响。节点数从一个变成node个,一次mget操作的IO从 O(1) 变成 O(node),并行情况下要等最慢的节点完成,串行的情况下需要依次等各个节点完成。
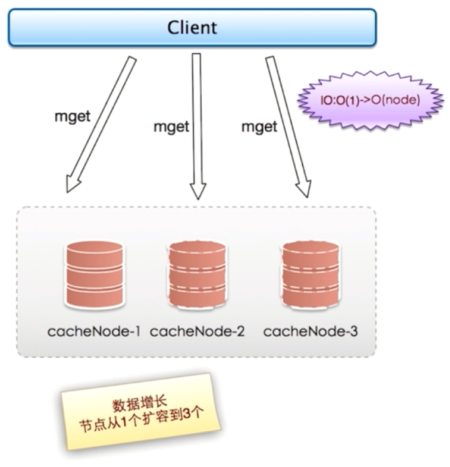
问题关键点:
- 更多的机器 != 更高的性能
- 批量接口需求(mget,mset等)
- 数据增长与水平扩展需求
优化IO的几种方案:
- 命令本身优化:例如慢查询keys、hgetall bigkey
- 减少网络通信次数
- 降低接入成本:例如客户端长连接/连接池、NIO等
优化批量操作的几种方法(Redis Cluster章节有详细解释):
- 串行mget
- 串行IO
- 并行IO
- hash_tag
# 八、热点key重建优化
缓存重建:从数据库查询到数据,缓存到redis的过程。
问题描述:热点key + 较长的重建时间
一个key对应的数据是热点数据,同时它的重建过程比较长,在第一次查询时开始重建缓存,但是重建过程中时间较长, 在重建期间有很多请求进来,由于缓存还没重建成功,所以这些请求都会去查询数据库并重建缓存。会造成数据库压力比较大,以及响应时间较慢的问题。过程如下图所示:
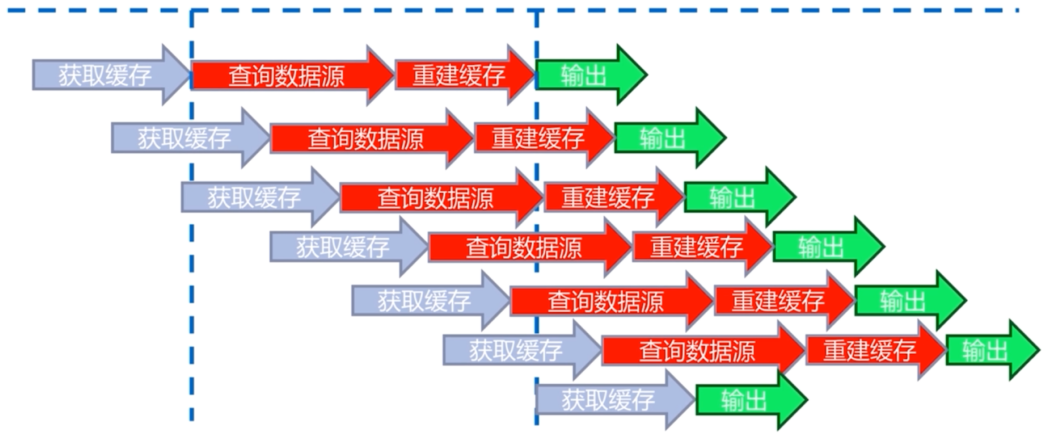
要解决这个问题,有以下三个目标:
- 减少重缓存的次数
- 数据尽可能一致
- 减少潜在危险
两个解决方案:
互斥锁(mutex key)
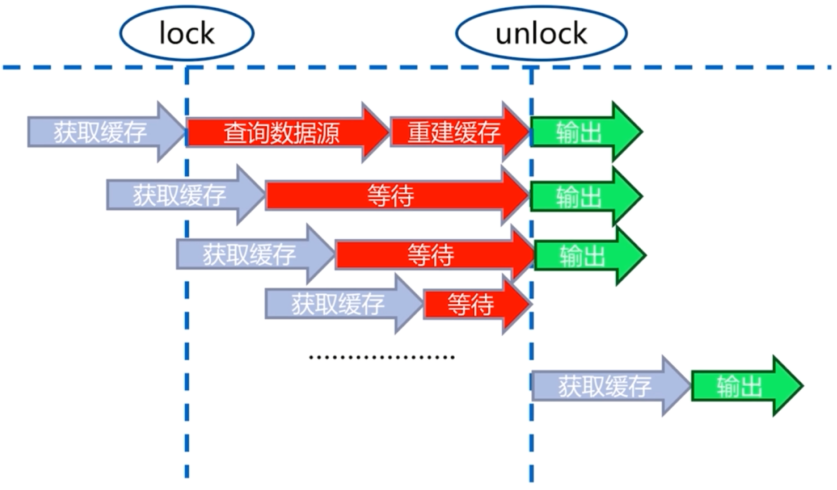
不需要大量重建过程,但是需要等待,可能大量线程等待。
// 伪代码 String get(String key) { String value = redis.get(key); if (value == null) { String mutexKey = "mutex:key:" + key; if (redis.set(mutexKey, "1", "ex 180", "nx")) { value = db.get(key); redis.set(key,value); redis.delete(mutexKey); } else { //其他线程休息50毫秒后重试 Thread.sleep(50); get(key); } } return value; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17永远不过期
- 缓存层面:没有设置过期时间(没有用expire)。
- 功能层面:为每个value添加逻辑过期时间,但发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
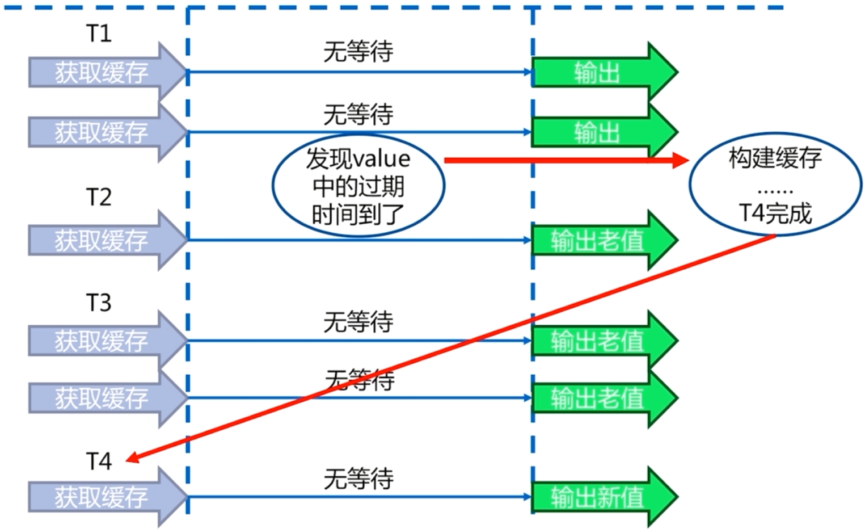
// 伪代码 String get(final String key) { V v = redis.get(key); String value = v.getValue(); long logicTimeout = v.getLogicTimeout(); if (logicTimeout >= System.currentTimeMillis()) { String mutexKey = "mutex:key:" + key; if (redis.set(mutexKey, "1", "ex 180", "nx")) { //异步更新后台异常执行 threadPool.execute(new Runnable) { public void run() { String dbValue = db.get(key); redis.set(key, (dbValue, newLogicTimeout)); redis.delete(keyMutex); } }); } } return value; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
两种方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | - 思路简单 - 保证一致性 | - 代码复杂度增加 - 存在死锁的风险 |
| key永不过期 | - 基本杜绝热点key重建问题 | -不保证一致性 - 逻辑过期时间增加维护成本和内存成本 |
# 九、总结
- 缓存收益:加速读写、降低后端存储负载。
- 缓存成本:缓存和存储数据不一致性、代码维护成本、运维成本。
- 推荐结合剔除、超时、主动更新三种方案共同完成。
- 穿透问题:使用缓存空对象和布隆过滤器来解决,注意它们各自的使用场景和局限性。
- 无底洞问题:分布式缓存中,有更多的机器不保证有更高的性能。有四种批量操作方式:串行命令、串行IO、并行IO、hash_tag。
- 雪崩问题:缓存层高可用、客户端降级、提前演练是解决雪崩问题的重要方法。
- 热点key问题:互斥锁、“永远不过期”能够在一定程度上解决热点key问题,开发人员在使用时要了解它们各自的使用成本。
参考文章: