 第03章-熔断器Hystrix
第03章-熔断器Hystrix
# Hystrix介绍
- Hystrix是主要用于处理延迟和容错的开源库
- Hystrix主要用于避免级联故障,提高系统弹性
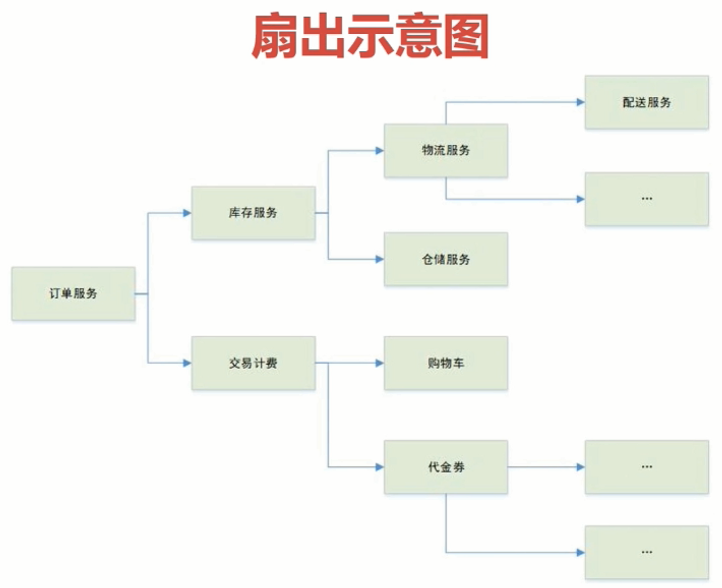
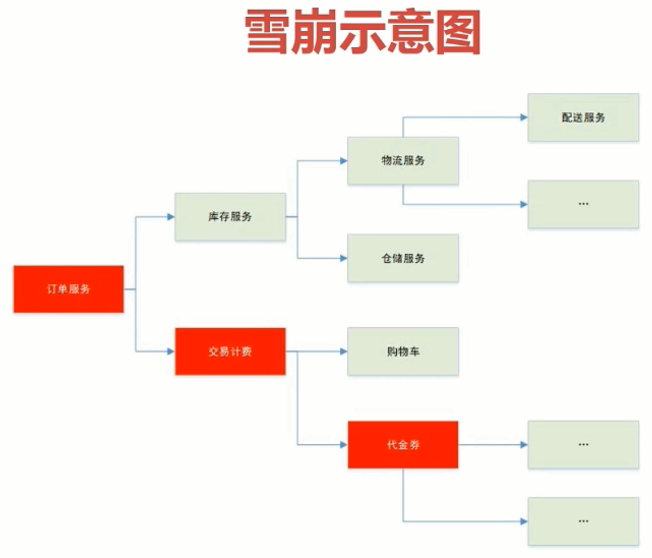
- Hystrix解决了由于扇出导致的“雪崩效应”
- Hystrix的核心是“隔离术”和“熔断机制”
# Hystrix依赖
<!-- Hystrix依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# Hystrix主要作用
- 服务隔离和服务熔断
- 服务降级、限流和快速失败
- 请求合并和请求缓存
- 自带单体和集群监控
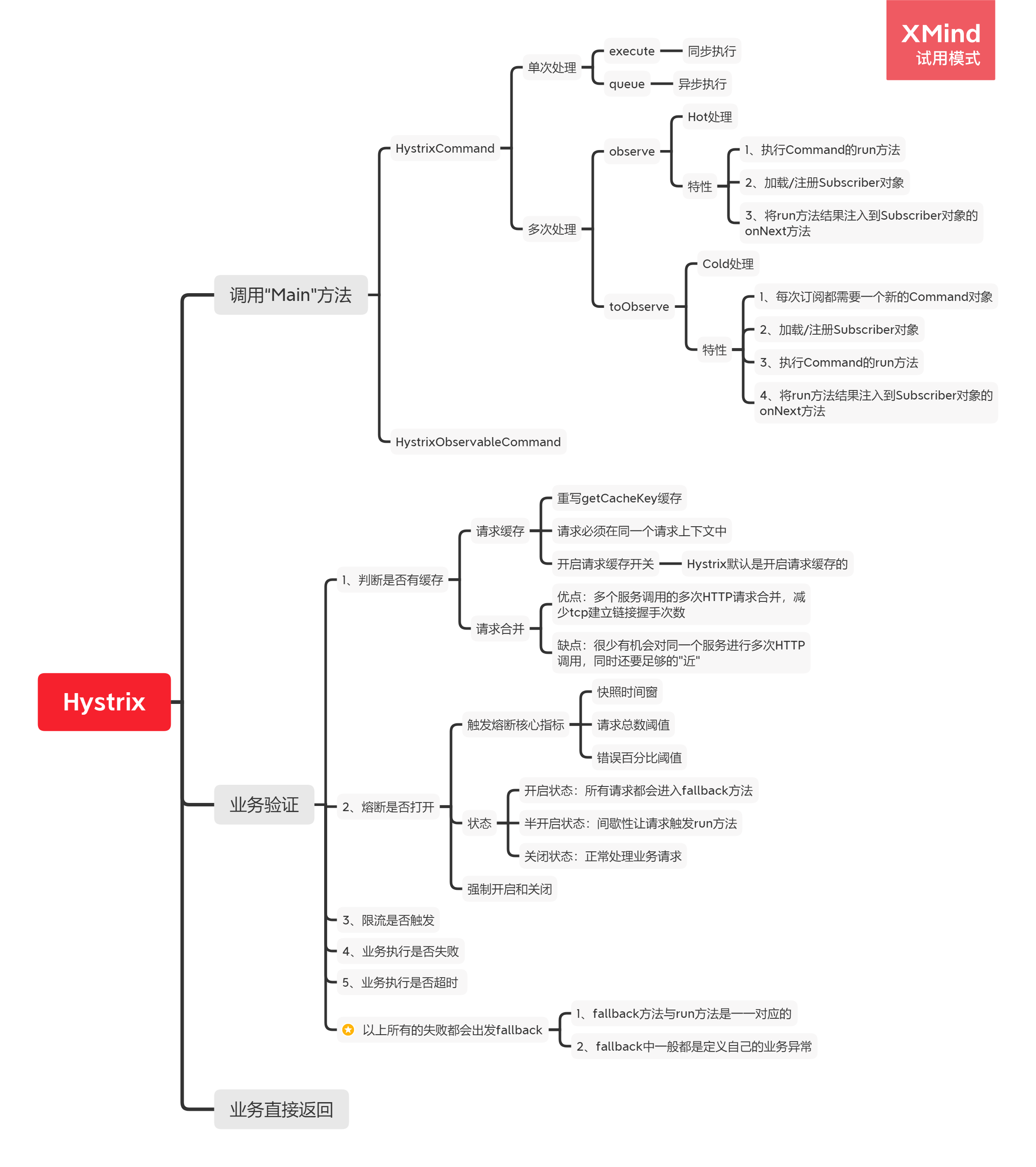
# Hystrix架构图介绍
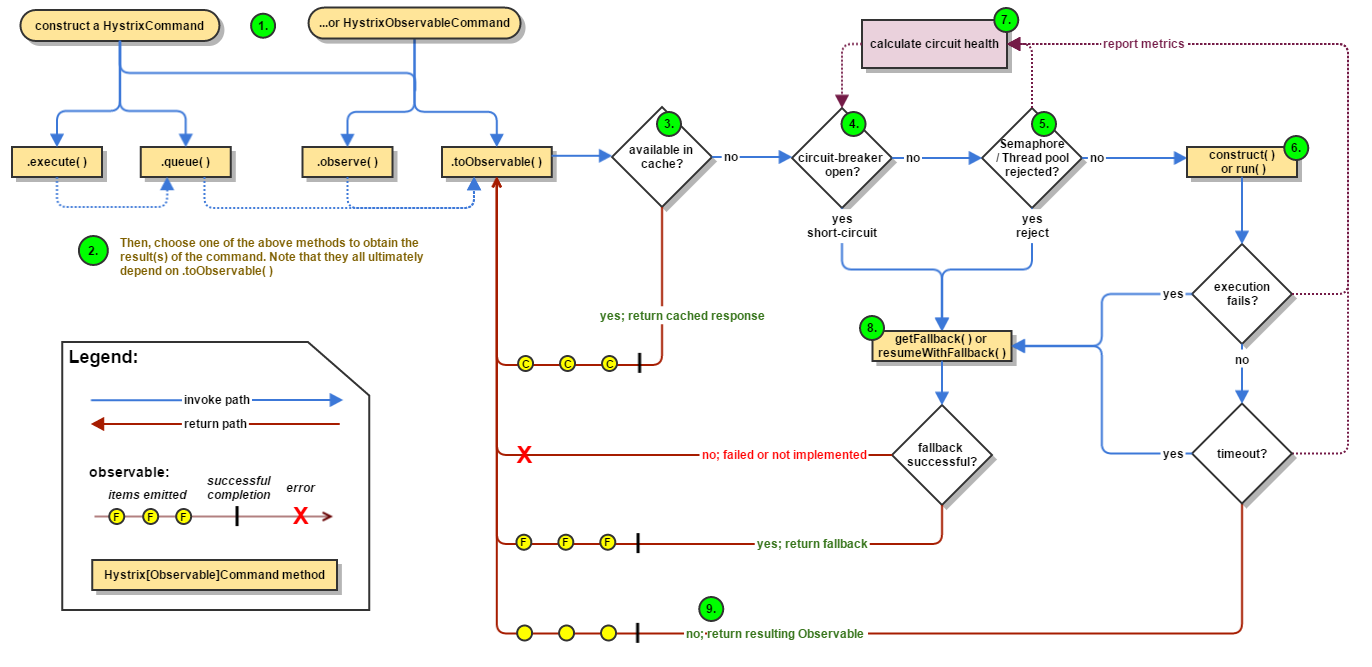
构建 HystrixCommand【依赖的服务返回单个的结果】 or HystrixObservableCommand【依赖的服务返回多个操作结果】对象【1】。
执行命令,以下四种方法中的一种【前两种方法仅适用于简单的HystrixCommand对象,而不适用于HystrixObservableCommand】【2】:
- execute(),同步,从依赖的服务返回一个单一的响应【或在发生错误的时候抛出异常】。
- queue(),返回Future对象,包含了服务执行结束时要返回的单一结果对象。
- observe():返回Observable对象。
- toObservable():返回Observable对象,也代表了操作的多个结果。
K value = command.execute(); Future<K> fValue = command.queue(); Observable<K> ohValue = command.observe(); //hot observable Observable<K> ocValue = command.toObservable(); //cold observable1
2
3
4检查缓存【3】,若当前命令的请求缓存功能是被启用的,并且该命令缓存命中,那么这个缓存的响应将立即以Observable形式返回。
检查断路器是否是打开状态【4】,如果断路器打开,则Hystrix不会执行命令,而是处理fallback逻辑【8】,否则检查是否有可用资源来执行命令【5】。
线程池/请求队列/信号量是否已满【5】,如果命令依赖服务的专有线程池和请求队列,或信号量已经被占满,那么Hystrix也不会执行命令,而是转到第【8】步。
Hystrix会根据我们编写的方法来决定采取什么样的方式去请求依赖服务【6】。
- HystrixCommand.run():返回一个单一的结果,或者抛出异常。
- HystrixObservableCommand.constract():返回一个Observable对象来发送多个结果或通过onError发送错误通知。
Hystrix向断路器报告成功、失败、拒绝和超时等信息,断路器通过维护一组计数器来统计这些数据,通过这些数据来决定是否要打开断路器【7】。
当命令执行失败时,Hystrix会进入fallback尝试回退处理,我们通常称为:服务降级。能够引起服务降级处理的情况:
- 熔断器打开。【4】
- 当前命令的线程池、请求队列、信号量被占满的时候。【5】
- HystrixCommand.run()或HystrixObservableCommand.constract()抛出异常时。【6】
当Hystrix命令执行成功之后,它会将处理结果直接返回或是以Observable的形式返回。
参考文档:
# Hystrix两种命令模式
- HystrixCommand 和 HystrixObservableCommand
- HystrixCommand 会以隔离的形式完成run方法调用
- HystrixObservableCommand 使用当前线程进行调用
# Hystrix配置
# GroupKey
- Hystrix中GroupKey是唯一必填项
- GroupKey可以座位分组监控和报警的作用
- groupKey将作为线程池的默认名称
# CommandKey
- Hystrix可以不填写CommandKey
- 默认CommandKey会通过反射类名命名CommandKey
- 再Setting中加入andCommandKey进行命名
# Hystrix请求特性
# Hystrix请求缓存
- Hystrix支持将请求结果进行本地缓存
- 通过实现getCachekey方法来判断是否取出缓存
- 请求缓存要求请求必须在同一个上下文
- 可以通过RequestCacheEnable开启请求缓存
# Hystrix请求合并
- Hystrix支持将多个请求合并成一次请求
- Hystrix请求合并要求两次请求必须足够“近”(默认阈值500ms)
- 请求合并分为局部合并和全局合并
- Collapser可以设置相关参数
# Hystrix隔离术
# Hystrix隔离之ThreadPoolKey
- Hystrix可以不填写ThreadPoolKey
- 默认Hystrix会使用GroupKey命名线程池
- 在Setting中加入andThreadPoolKey进行命名
# Hystrix隔离介绍
- Hystrix提供了信号量和线程两种隔离手段
- 线程隔离会在单独的线程中执行业务逻辑
- 信号量隔离在调用线程上执行
- 官方推荐优先线程隔离
Hystrix隔离示意图
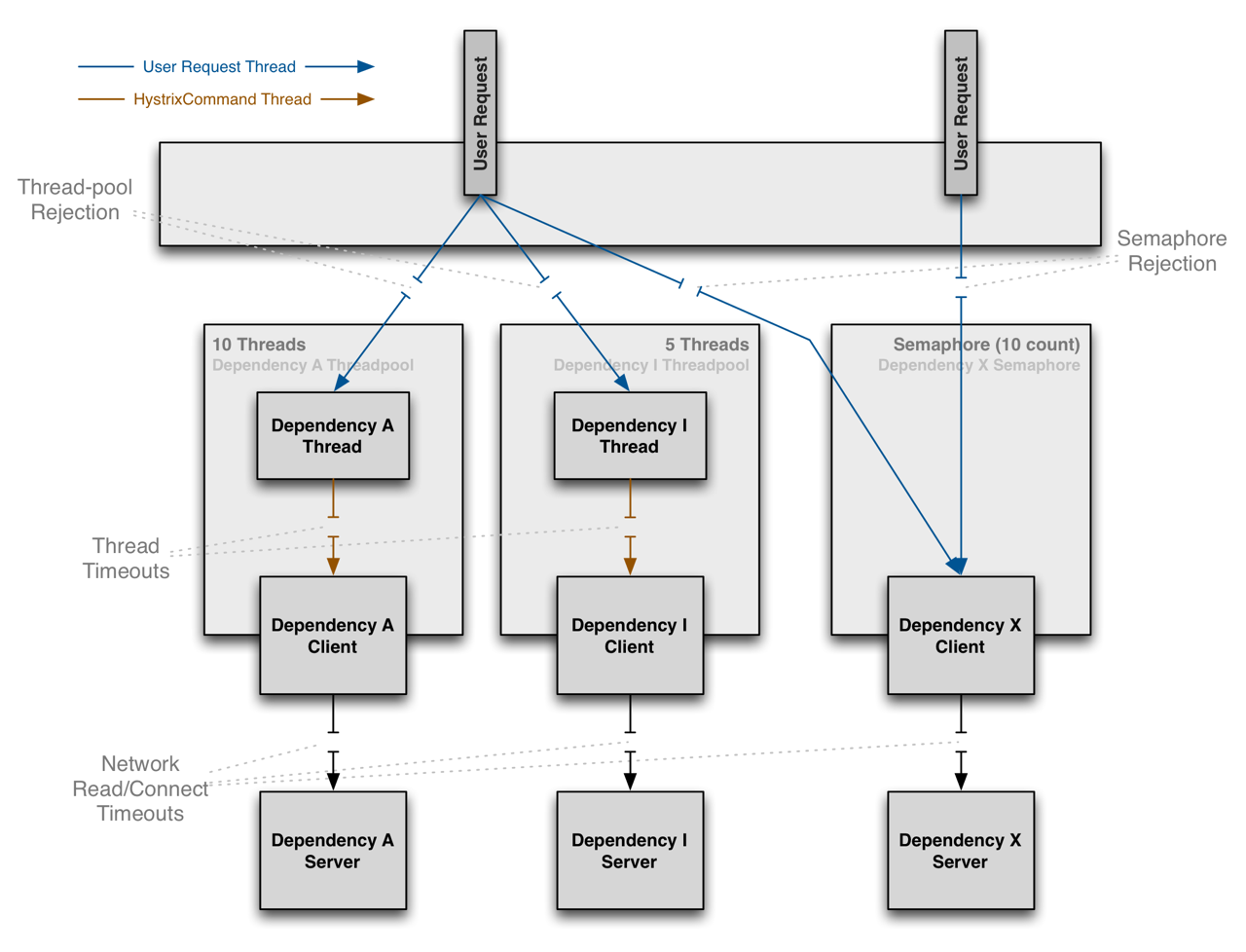
# 线程隔离
- 应用自身完全受保护,不会受其他依赖影响
- 有效减低接入新服务的风险
- 依赖服务如果出现问题,应用自身可以快速反应问题
- 可以通过实时刷新动态属性减少依赖问题影响
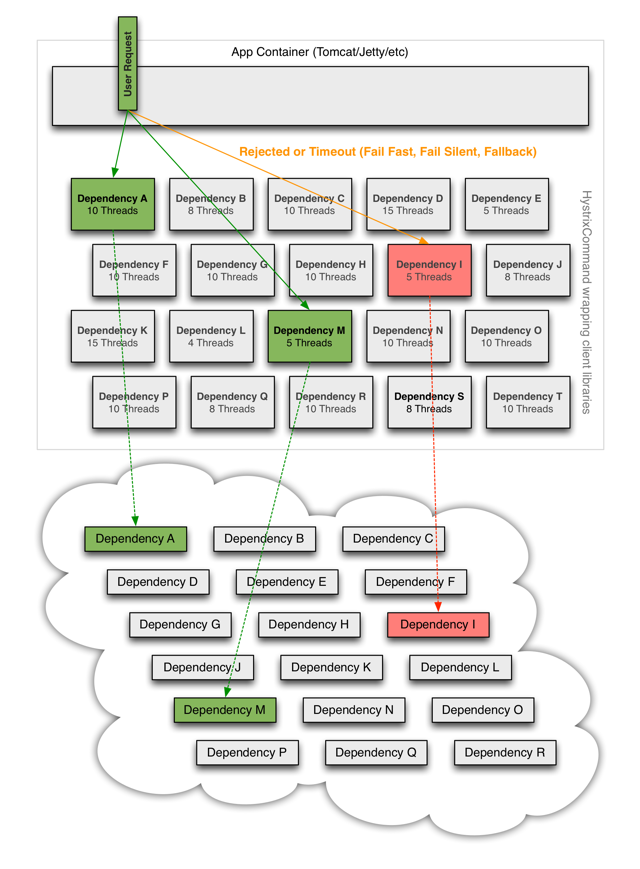

# 信号量隔离
- 信号量隔离是轻量级的隔离术
- 无网络开销的情况推荐使用信号量隔离
- 信号量是通过计数器与请求线程比对进行限流的
# Hystrix降级处理
# Hystrix降级介绍
- 降级是一种“无奈”的选择,就是所谓的备胎
- Command降级需要实现fallback方法
- ObserveCommand降级实现resumeWithFallback方法
# 降级触发原则
- HystrixBadRequestException以外的异常
- 运行超时活熔断器处于开启状态
- 线程池或信号量已满
# 快速失败
- Hystrix提供了快速失败的机制
- 当不实现fallback方法时会将异常直接抛出
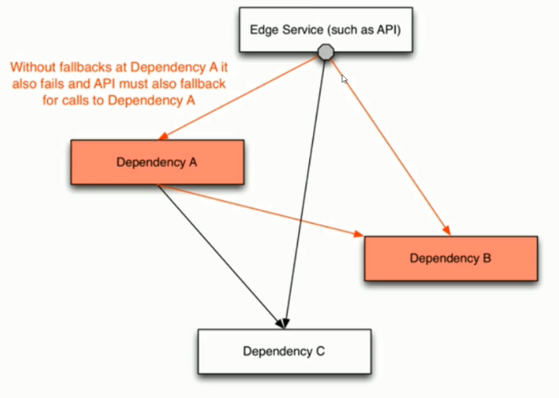
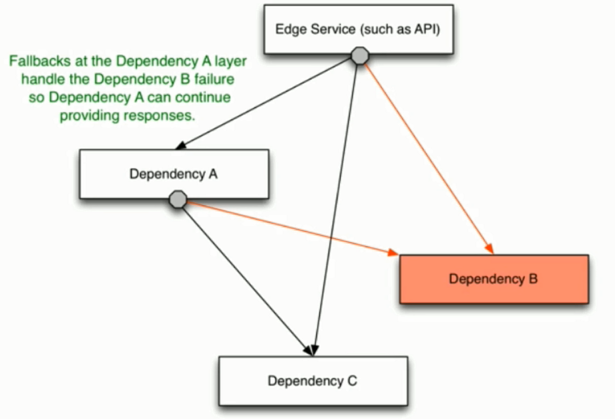
# Hystrix熔断机制
# 熔断器介绍
- 熔断器是一种开关,用来控制流量是否执行业务逻辑
- 熔断器核心指标:快照时间窗(一个时间段)
- 熔断器核心指标:请求总数阈值(快照时间窗内的请求总数)
- 熔断器核心指标:错误百分比阈值(快照时间窗内错误请求比例)
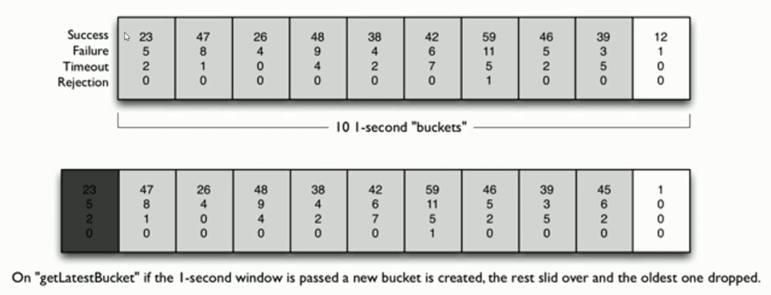
Hystrix在一个请求时间窗内,请求总数达到阈值,并且错误百分比达到阈值才会触发熔断
# 熔断器状态
- 熔断器开启:所有请求都会进入fallback方法
- 熔断器半开启:间歇性让请求触发run方法
- 熔断器关闭:正常处理业务请求
- 默认情况下熔断器开启5s后进入半开启状态
半开启状态下会间歇性放行一个请求去执行业务逻辑,去检测业务是否恢复,如果恢复了再关闭熔断器
# Hystrix监控平台
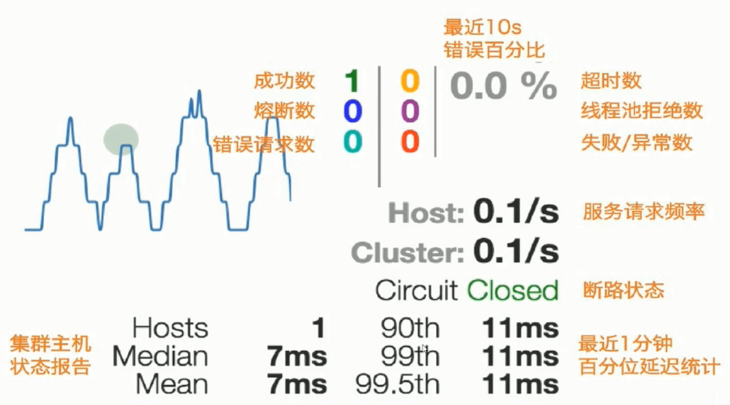
# Hystrix线程池设计官方建议

# 附录
# 配置参数
Command基础配置
| 配置 | 配置描述 |
|---|---|
| execution.isolation.strategy | 隔离类型:THREAD-线程隔离,SEMAPHORE-信号量隔离 |
| execution.timeout.enabled | 超时检查是否开启 |
| fallback.enabled | 是否开启降级处理 |
请求上下文配置
| 配置 | 配置描述 |
|---|---|
| requestCache.enabled | 是否开启请求缓存,默认为true |
| requestLog.enabled | 是否开启请求日志,默认为true |
| maxRequestsInBatch | 设置批处理中允许的最大请求数 |
| timerDelayInMilliseconds | 设置批处理创建到执行之间的毫秒数 |
线程池相关配置
| 配置 | 配置描述 |
|---|---|
| coreSize | 配置线程池大小,默认为10 |
| keepAliveTimeMinutes | 配置核心线程数空闲时keepAlived时长,默认1分钟 |
| maxQueueSize | 配置线程池任务队列大小,默认为-1 |
| maximumSize | 线程池中线程的最大数量,默认值是 10 |
| queueSizeRejectionThreshold | 任务队列的请求上限,默认值是10 |
| allowMaximumSizeToDivergeFromCoreSize | 是否开启最大线程数 |
| execution.isolation.thread.timeoutInMilliseconds | 设置超时时间 |
| execution.isolation.thread.interruptOnTimeout | 请求超时是否中断任务 |
| execution.isolation.thread.interruptOnCancel | 请求取消是否终端任务 |
信号量隔离配置
| 配置 | 配置描述 |
|---|---|
| execution.isolation.semaphore.maxConcurrentRequests | 任务执行信号量最大数 |
| fallback.isolation.semaphore.maxConcurrentRequests | 失败任务执行信号量最大数 |
熔断机制相关配置
| 配置 | 配置描述 |
|---|---|
| circuitBreaker.enabled | 是否开启熔断器 |
| circuitBreaker.requestVolumeThreshold | 启用熔断器功能窗口时间内的最小请求数 |
| circuitBreaker.sleepWindowInMilliseconds | 半熔断开启时间 |
| circuitBreaker.errorThresholdPercentage | 开启熔断的失败率阈值 |
| circuitBreaker.forceOpen | 强制开启熔断器 |
| circuitBreaker.forceClosed | 强制关闭熔断器 |
metrics相关配置
| 配置 | 配置描述 |
|---|---|
| metrics.rollingStats.timeInMilliseconds | 此配置项指定了窗口的大小,单位是 ms,默认值是 1000 |
| metrics.rollingStats.numBuckets | 生成统计数据流时滑动窗口应该拆分的桶数 |
| metrics.rollingPercentile.enabled | 是否统计方法响应时间百分比,默认为 true |
| metrics.rollingPercentile.timeInMilliseconds | 统计响应时间百分比时的窗口大小 |
| metrics.rollingPercentile.numBuckets | 统计响应时间百分比时滑动窗口要划分的桶用,默认为6 |
| metrics.rollingPercentile.bucketSize | 统计响应时间百分比时,每个滑动窗口的桶内要保留的请求数 |
| metrics.healthSnapshot.intervalInMilliseconds | 它指定了健康数据统计器中每个桶的大小,默认是 500ms |
# 参考文档
编辑 (opens new window)
上次更新: 2023/06/04, 12:34:19