 第06章-MySQL架构
第06章-MySQL架构
# 一、主从复制
# 1.1 主从复制的过程
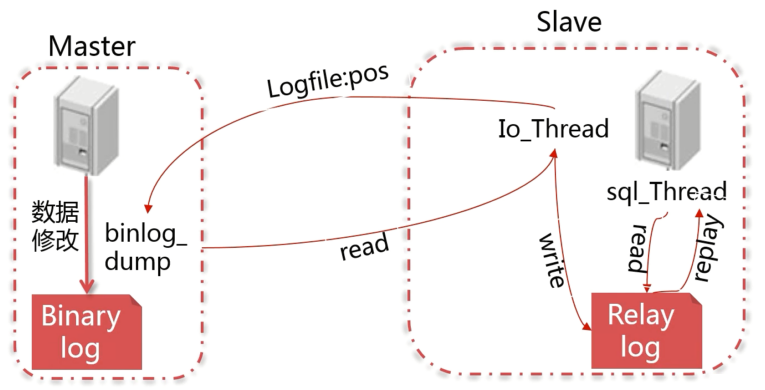
- Master 节点将数据记录到 binlog 中
- Slave 从指定位置开始去读 Master 节点的 binlog
- Slave 读取工作由 IO 线程进行,和 Master 的 binlog_dump 线程建立连接,发送同步的偏移量,拉取 binlog数据
- Slave 将读取到的 binlog 数据存到中继日志(Relay log)中,格式和 binlog 完全一致
- Slave 上的 sql 线程读取中继日志中的内容进行重放,完成数据同步
Slave 通过 sql 线程重放的数据可以通过配置控制是否写入 Slave 节点的 binlog 中。根据 binlog 的格式不同,重放的方式也不同,基于 sql 的 binlog 是在 Slave 上重新执行改 sql;基于行的 binlog 则是在对应的行上直接应用对数据行的修改。
注意查看 Master 是否开启了二进制日志,如果原先没有开启,后续开启的话需要重启 MySQL。
# 1.2 异步复制和半同步复制
# 1.2.1 异步复制
下面在一主多从的场景下介绍异步复制
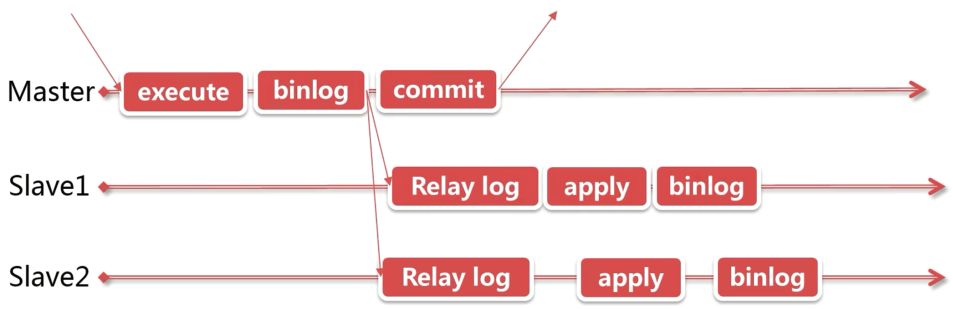
- MySQL 在 Master 上执行事务修改数据,事务被记录到 binlog 中并 commit
- Master 对数据的修改记录到 binlog 中,会从 Slave 的 IO 进程传输到 Slave 的中继日志
- Slave 读取中继日志进行重放,并根据配置决定是否将事件写入自身的 binlog 中
这种模式下主从的数据不是同步的,不同 Slave 节点的数据也不是同步的。这种方式如果主库完成了数据的修改但是没有同步到从库上,主库发生了宕机,这时候就会发生数据求实的情况。
# 1.2.2 半同步复制
MySQL5.6 版本引入了半同步复制,需要安装半同步插件 install plugin rpl_semi_sync_master
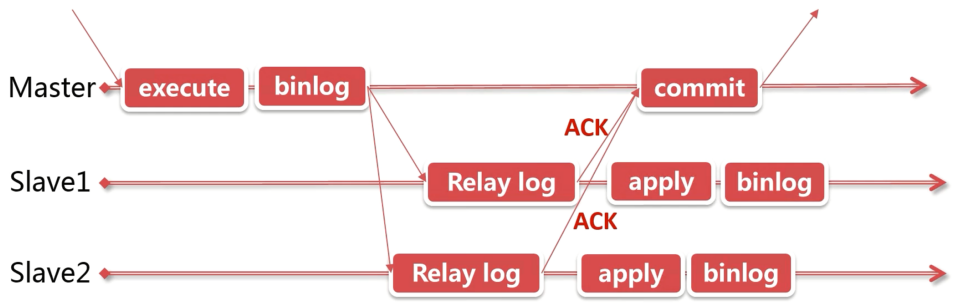
半同步复制与异步复制的不同点在于,Slave 收到数据后向 Master 发送一个确认消息,同时 Master 的 commit 操作被阻塞,Master 只有收到 Slave 的确认消息后才会执行 commit,将结果返回给客户端。其他步骤与异步复制相同。
可以为半同步复制设置一个过期时间,超过过期事件后,主节点不再等待,同步过程降级为异步复制。这种模式即使主节点宕机,由于没收到从节点的 ack,也不会 commit 事务,进而大大降低了数据丢失的可能性。
# 1.3 主从复制的配置
主从复制配置步骤
Master 节点操作:
- 开启 binlog(必须)开启 gtid(可选)
- 建立同步所用的数据库账号
- 使用 master_data 参数备份数据库
- 把备份文件转输到 Slave 服务器
Slave 节点操作:
- 开启 binlog(可选)开启 gtid(可选)
- 恢复 Master 上的备份数据库
- 使用
change master命令配置链路 - 使用
start slave命令启动复制
详细步骤 TODO
# 1.4 日志点复制和 GTID 复制
# 1.4.1 日志点复制
什么是基于日志点的复制
- 传统的主从复制方式
- Slave 请求 Master 的增量日志依赖于日志偏移量
- 配置链路时需指定
master_log_file和master_log_pos参数
随着事务的提交,binlog 和偏移量的值都是不断变化的,而且每一个实例中 binlog 的文件名都是不同的,偏移量也是针对某一个具体的文件而言的。同一个事务在 Master 和 Slave 中的 binlog 和偏移量都是不同的。一旦出现 Master 宕机,需要做主从迁移的时候,很难从一个新的 Master 中找到正确的 binlog 和偏移量。这也是为什么在 5.6 中引入 gtid 主从复制的一个原因。
# 1.4.2 GTID 复制
什么是基于 GTID 的复制
GTID = source_id:transaction_id
GTID 即全局事务 id,在一个主从架构中,每一个事务的 GTID 都是不同的。GTID 由两部分组成,第一步分是执行这个事务主机的 uid,即上面的 source_id,第二部分是这个主机上执行过的事务的数量,是一个随着事务提交递增的 ID,两部分之间通过冒号分隔。
GTID 的两个作用:
- 根据 source_id 分析出事务是在哪台机器上提交的。
- 可以方便的对 MySQL 实例进行故障转移,我们只需要选择从原 Master 同步最多事务数量的 Slave 成为新的 Master,让别的 Slave 成为该节点的丛节点即可。
基于 GTID 的主从复制,只需要 Slave 提供给 Master 已经同步过的 GTID 的值即可确定同步进度。比基于日志点偏移量的方式更加的安全高效。配置链路时,Slave 可以根据已经同步的事务 ID 继续自动同步。
# 1.4.3 日志点和 GTID 复制对比
两种主从复制对比
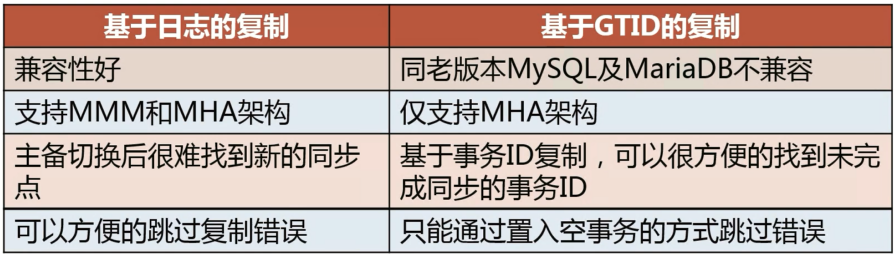
两种复制方式如可选择,当需要满足以下条件时,选择基于日志点的复制,其他情况优先选择基于 GTID 的复制。
- 需要兼容老版本 MySQL 及 MariaDB,只能使用日志点复制
- 需要使用 MMM 架构,只能选择日志点复制
# 二、高可用架构
# 2.1 MMM 和 MHA 架构
MMM 和 MHA 高可用架构的作用
对主从复制集群中的 MASTER 的健康进行监控
当 MASTER 宕机后把写 VIP 迁移到新的 MASTER
应用连接数据通常是通过数据库所在的服务器 IP 进行连接的,VIP 就是独立于数据库服务器 IP 之外的一个 IP,因此称之为虚 IP。虚 IP 可以按需要绑定在任意一个具有 Master 职等的服务器上。同一时间只能有一个 VIP,应用通过 VIP 访问数据库。
重新配置集群中的其它 Slave 对新的 MASTER 同步
# 2.2 MMM 架构
# 2.2.1 MMM 架构介绍
MMM 架构(Master-Master replication manager for Mysql),从名字可以看出 MMM 架构是有两个 Master 的,这似乎和一个主从架构中只有一个 Master 冲突,其实说的是同一时间只能有一个 Master,MMM 架构中的两个 Master 是互为主备的关系,同一时间只有一个节点作为 Master,另一个还是作为其 Slave 存在的。
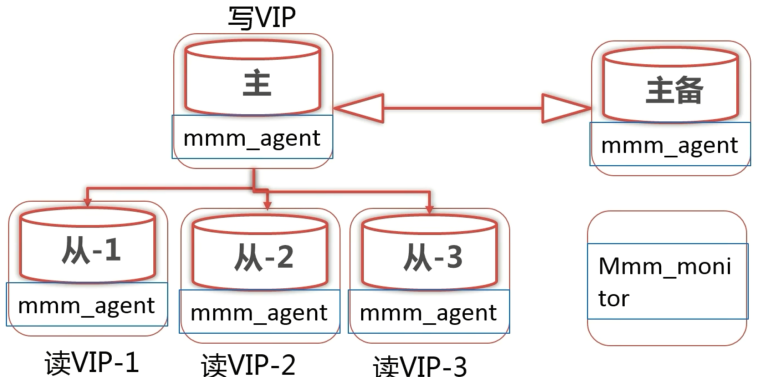
- 在 MMM 架构中有两台 Master 节点,一个作为主使用,另一个作为主备使用,并且主和主备之间是进行双向同步的。即主作为主备的 Slave,主备作为主的 Slave。
- 同时还有多态 Slave 节点,初始状态下这些 Slave 都从主服务器同步数据。
- MMM 工具会为主服务器分配一个写 VIP,同时为从服务器都分配一个读 VIP。也就是说 MMM 不仅可以监控主服务器,还可以监控从服务器。
- 读 VIP 可以在多个 Slave 之间迁移,写 VIP 只能在主和主备之间迁移。
- 当主服务器宕机时,主和主备之间的同步也会终端,MMM 会将 Slave 节点都挂到主备上,并且把写 VIP 也迁移到主备上。
- 当 Slave 节点宕机时,MMM 会将改节点上的读 VIP 迁移到其他 Slave 节点上。
- 同时还需要一台服务器监控各节点的健康状况,即 MMM 的监控服务器,在这台服务器中需要安装 MMM 的 monitor 组件。在其他的 MySQL 节点上需要安装 MMM 的 agent 组件。
# 2.2.2 MMM 故障转移步骤
SLAVE 服务器上的操作:
完成原主上已复制的日志的重放(可能存在还没重放完成的中继日志)
使用
Change Master命令配置新主服务器由于异步复制进度的差异,这里无法保证主备服务器的数据比所有的 Slave 更接近原主服务器。此时将 Slave 迁移到主备服务器上进行同步,必然会造成数据不一致,从而中断主从复制的线程。这应该是 MMM 存在的最大的一个问题。
主备服务器上的操作:
- 设置
read_only=off(除主服务器外都是 read_only 的) - 迁移写 VIP 到新主服务器
完成了上述操作,MMM 就完成了主服务器宕机的故障转移。
# 2.2.3 MMM 所需资源

- 2n+1 个 IP 地址是因为每个 MySQL 服务器都需要两个 IP,一个物理 IP,一个用于读写的 VIP。另外一个 IP 提供给监控服务器。
# 2.2.4 MMM 配置步骤
- 配置主主复制的集群架构
- 安装 Centos 的 YUM 扩展包
- 安装所需的 Perl 支持包
- 安装 MMM 管理工具包
- 配置并启用 MMM 服务
# 2.2.5 MMM 优缺点
MMM 架构的优点
- 提供了读写 VIP 的配置,使读写请求都可以达到高可用
- 工具包相对完善,不需要额外开发脚本
- 成故障转移后,可以持续对 MySQL 集群进行高可用监控
MMM 架构的缺点
- 故障切换简单粗暴易丢事务(主备使用 5.7 以后的半同步复制)
- 不支持 GTID 的复制方式(自行修改 perl 脚本实现)
- 社区不活越,很久未更新版本
# 2.2.6 MMM 适用场景
- 使用基于日志点的主从复制方式
- 使用主主复制的架构
- 需要考虑读高可用的场景(MHA 不监控 Slave 的宕机)
# 2.3 MHA 架构
# 2.3.1 MHA 架构介绍
MHA(Master High Availability Manager and Toolsfor MySQL)
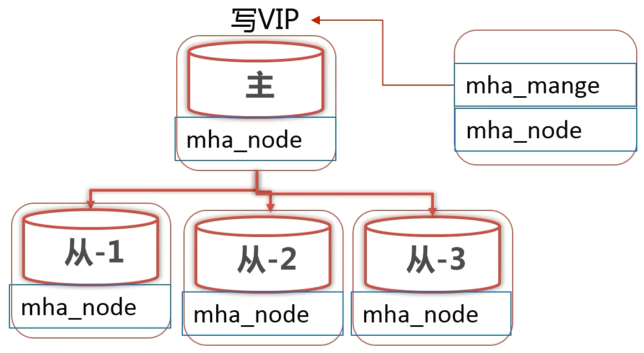
MHA 架构初始状态有一个 Master 和多个 Slave,同时还有一个 MHA 的监控服务器。
在 MHA 监控服务器上需要安装 nha_manage 和 mha_node 组件,被监控的 MySQL 服务器上只需要安装 mha_node 组件。
当 MHA 监控到 Master 宕机后, 会选择一个数据最接近 Master 的 Slave 作为新的 Master,并将写 VIP 迁移到新的 Master 节点上。
# 2.3.2 MHA 配置步骤
- 配置一主多从的复制架构
- 安装 CentOS 的 Yum 扩展源及依赖包
- 配置集群内各主机的 SSH 免认证(MHA 通过 SSH 进行协调节点工作)
- 在各节点安装 mha_node 软件
- 在管理节点安装 mha_manager
- 配置并启动 MHA 管理进程
# 2.3.3 MHA 架构优缺点
MHA 架构的优点
- 支持 GTID 的复制方式和基于日志点的复制方式
- 可从多个 Slave 中选举最适合的新 Master
- 会尝试从旧 MASTER 中尽可能多的保存未同步日志
MHA 架构的缺点
- 未必能获取到旧主未同步的日志(使用 5.7 以后的半同步复制)
- 需要自行开发写 VIP 转移脚本
- 只监控 MASTER 而没有对 Slave 实现高可用的办法
# 2.3.4 MHA 适用场景
- 使用基于 GTID 的复制方式
- 使用一主多从的复制架构
- 希望更少的数据丢失的场景
# 三、主从延迟
# 3.1 主从复制延迟原因
结合下图,从主从复制的各个阶段分析主从复制延迟的原因
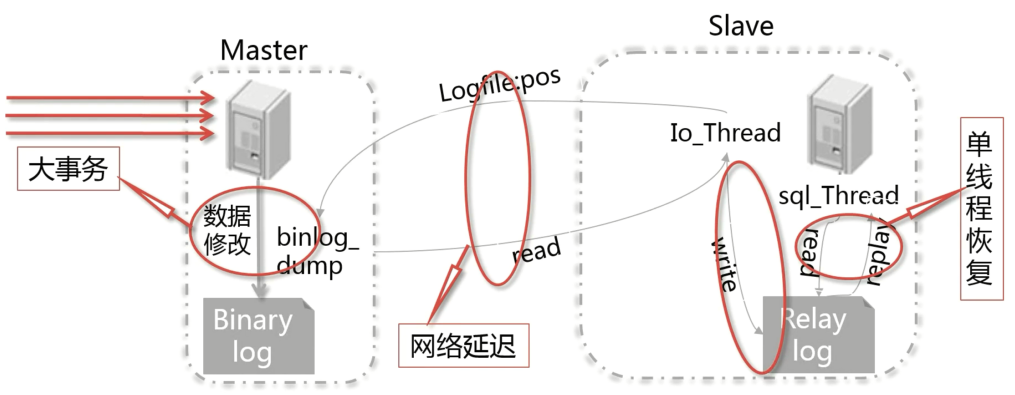
- 在异步复制过程中,事务只有在主库提交之后才写如 binlog 中,这之情况下如果在主库上执行了一个大事务就会对主从延迟产生影响。
- 传输阶段网络延迟产生的影响。
- Slave 将数据写入中继日志阶段,因为是顺序写,所以对主从延迟的影响可以忽略。
- Slave 重放阶段只有一个 sql 线程进行重放,而 Master 上是并发写数据的,效率不一致会影响主从复制。
# 3.2 减小主从延迟方案
针对不同情况造成的主从延迟,有不同的解决方案
- 针对大事务
- 大事务:数万行的数据更新以及对大表的 DDL 操作
- 化大事务为小事务,分批更新数据
- 使用 pt-online-schema-change 工具进行 DDL 操作
- 针对网络延迟
- 减小单次事务处理的数据量以减少产生的日志文件大小
- 减少主上所同步的 Slave 的数量,减小 Master 网卡压力
- 针对单线程恢复
- 由主上多线程的写入从上单线程恢复引起的延迟,使用 MySQL5.7 之后的多线程复制
- 使用 MGR 复制架构
# 四、MGR 复制架构
# 4.1 MGR 复制架构介绍
MGR(MySQL Group Replication),是基于现有的 MySQL 复制架构来实现的一个 MySQL 工具,最早出现在 MySQL5.7。是一种不同于异步复制的多 Master 复制集群。
MGR 中的复制组(Group)是一组彼此之间可以进行消息通信来保证数据一致性的 MySQL 服务器,而在复制组中,每一台 MySQL 服务器都可以独立完成数据的更新,即 MGR 中可以实现多个主同时对数据进行修改。
MGR 是官方推出的一种基于 Paxos 协议的复制。Paxos 协议是一种分布式一致性的算法,主要为了解决多个节点并发操作中如何保证一致性的问题,协议要求必须主从节点中大多数节点同意情况下数据才能被更新。
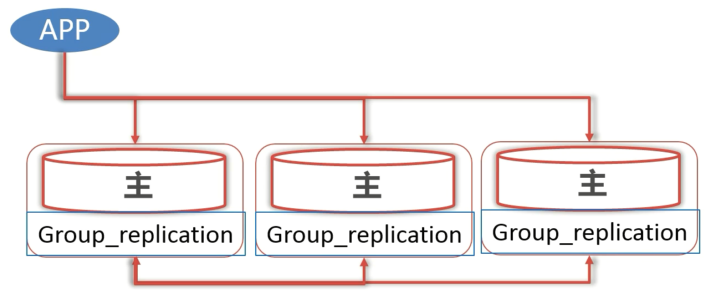
MGR 复制架构中,每一个节点都要安装 group_replication 插件,都可以当作 Master 来使用。每个节点之间通过主从复制和 Paxos 协议进行数据同步和更新的。客户端可以通过任意一个节点对数据进行修改
# 4.2 MGR 复制实现原理
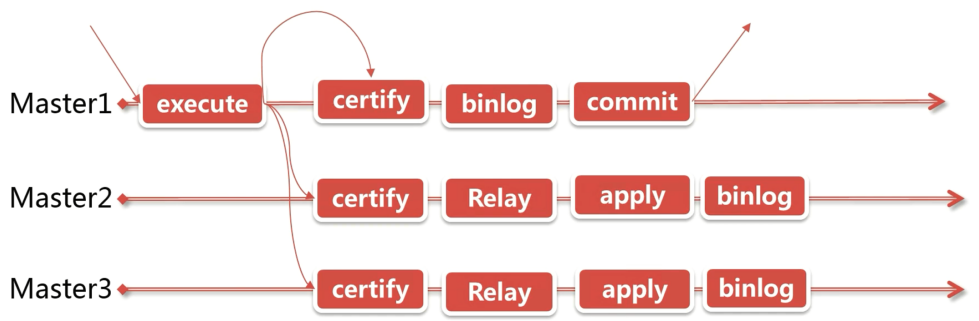
客户端对 MGR 中的一个节点发送修改数据请求,这个节点会将修改数据对其他数据进行广播,只有当集群中的大多数节点认可这个数据修改之后,这个请求才会得到执行。
MGR 集群可以保证事务在各个节点中执行的顺序是一致的,但是由于事务在各个节点中是分别进行提交的,所以数据在各节点中多少还会有延迟的情况,但是比异步复制好很多。
MGR 不仅支持多主模式,还支持单主模式,官方更推荐使用单主模式。在多主模式下更容易出现死锁和写冲突,并且也不能减小写负载。
# 4.3 单主模式和多主模式
# 4.3.1 单主模式
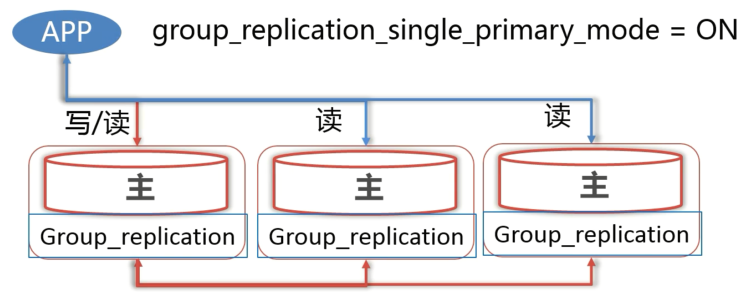
- 单主模式下客户端只能通过 primary 节点进行读写操作,其他节点只能处理读请求。
- primary 由 MGR 集群选出,如果 pirmary 节点宕机会自动选举出新的 primary 节点。
- 单主模式下需要配置
group_replication_single _primary_mode=ON。
# 4.3.2 多主模式
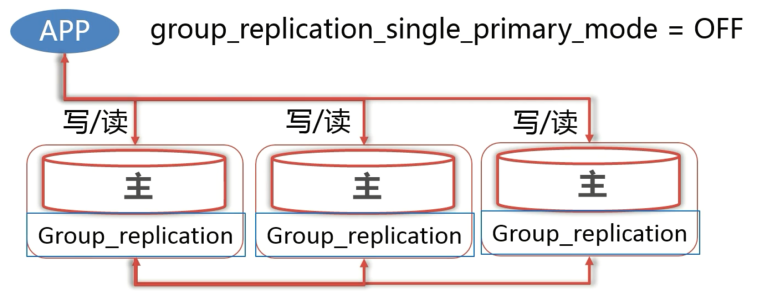
- 多主模式下每个节点既可以处理读请求也可以处理写请求。
- 由于各个节点都可以处理写请求,所以各个节点之间事务执行的先后顺序就需要更多的协调,同时也更容易产生数据冲突。冲突出现的时候,MGR 会将某一个节点的数据进行回滚。
- 由于每个节点都会写入相同的数据,也不会减小节点的写负载,所以更推荐使用单主模式。
- 多住模式需要配置
group_replication_single_primary_mode=OFF。
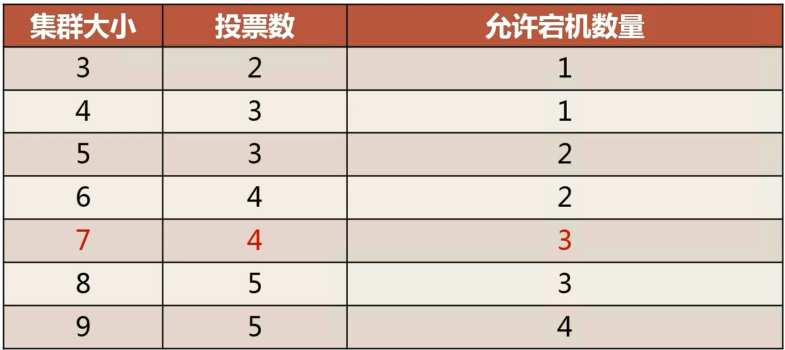
# 4.4 MGR 所需资源
由于 MGR 集群采用多数节点认同的方式更新数据,所以至少需要 3 个节点,最多支持 9 个节点。
如下表所示,当集群大小为 3 节点时,需要 2 个节点认同才能正常执行事务,所以只允许 1 个节点宕机,其他情况如表所示。
# 4.5 MGR 配置步骤
MGR 集群是使用 MySQL 插件的形式,比 MMM 和 MHA 第三方工具形式要简单些,步骤如下:
- 安装 group_replication 插件=
- 在第一个实列上建立复制用户
- 配置第一个组实例
- 把其它实制加入组
详细步骤 TODO
# 4.6 MGR 复制的优缺点
MGR复制架构的优点
- Group Replication 组内成员间基本无延迟
- 可以支持多写操作,读写服务高可用
- 数据强一致,可以保证不丢失事务
MGR复制架构的缺点
- 只支持 InnoDB 存储引擎的表,并且每个表上必须有一个主键
- 单主模式下很难确认下一个 primary
- 只能用在 gtid 模式的复制形式下,且日志格式必需为 row
# 4.7 MGR 适用场景
- 对主从延迟十分敏感的应用场景
- 希望可以对读写提供高可用的场景
- 希望可以保证数据强一致的场景。
# 五、读写负载问题
解决读负载大问题
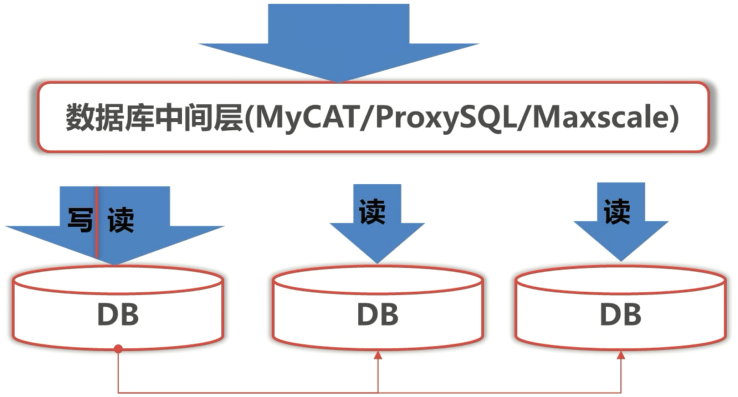
- 为原 DB 增加 Slave 服务器
- 进行读写分离,把读分担到 Slave
- 增加数据库中间层,进行负载均衡
解决写负载大问题
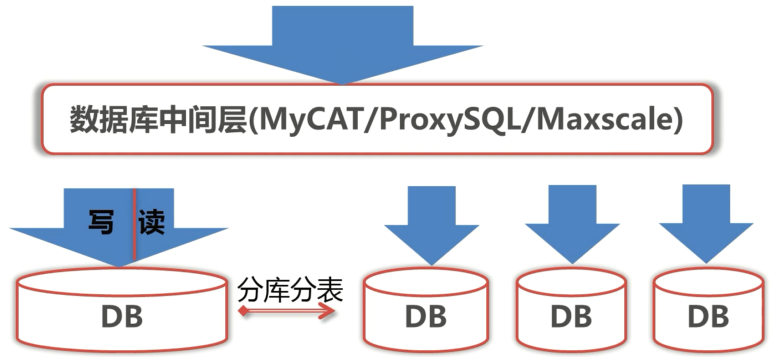
- 进行分库分表